 Streaming Learning Center Where Streaming Professionals Learn to Excel
Streaming Learning Center Where Streaming Professionals Learn to Excel

Related Articles




This article is about a video lesson that computes the bandwidths savings afforded by the FFmpeg-based implementations of VP9 (libvpx-VP9), H.264 (x264), HEVC (x265), and AV1 (libaom-AV1). The lesson uses the Netflix convex hull analysis to build unique encoding ladders for each test clip and codec and shows why BD-Rate figures don’t accurately predict real-world savings. Towards the end, it presents a technique for computing the real-world impact of implementing a new codec. Sadly, for libvpx-vp9, the answer is likely not much.
You can watch the video below, work through the highlights here, or do both. Here’s the video. Click over to YouTube to use the table of contents feature to access each major section.
Here are the highlights.
Contents
Command Strings
I encoded all files in FFmpeg using command strings formulated in this article (libaom-AV1, x264, x265) and this article (libvpx-vp9).
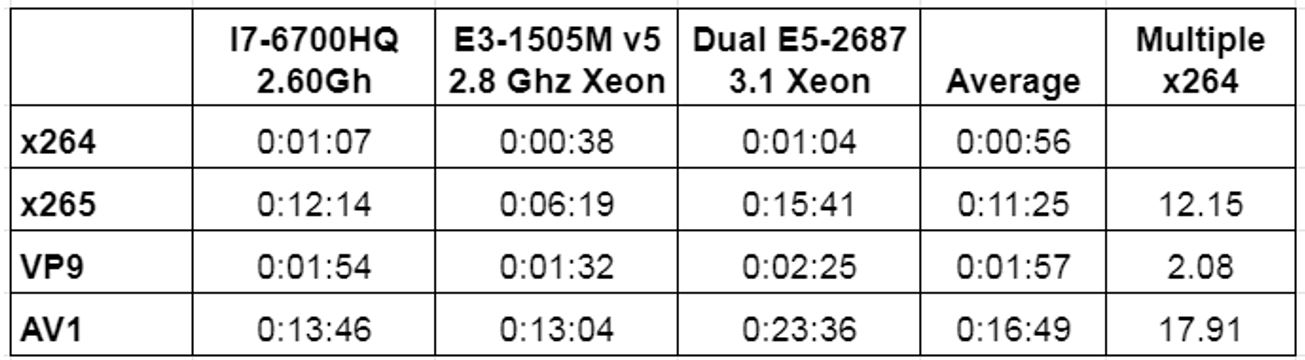
Encoding Times
These results were so surprising that I ran my tests on three separate computers. On all three, x265 in veryslow mode was much, much slower than libvpx-vp9. I checked back over several articles, including here, and here, and found the same relationship between x264 veryslow and x265 veryslow.
So, I think those who find libvpx-vp9 slow to encode were using preset 0 which extends encoding time with minimal beneficial impact on encoding quality. With x265, I used veryslow because VP9 was outperforming x265 medium and I figured most producers would use veryslow to get better quality.
Creating the Encoding Ladders
This was one of the most challenging aspects of the process. In order to fairly compare x265, x265, libaom-av1, and libvpx-vp9, I had to create the ideal encoding ladder for each clip with x264, and then create the ideal ladder for that clip for each codec. A fixed ladder for all clips wouldn’t work, and a custom ladder for each clip used with each codec wouldn’t maximize the performance benefit.
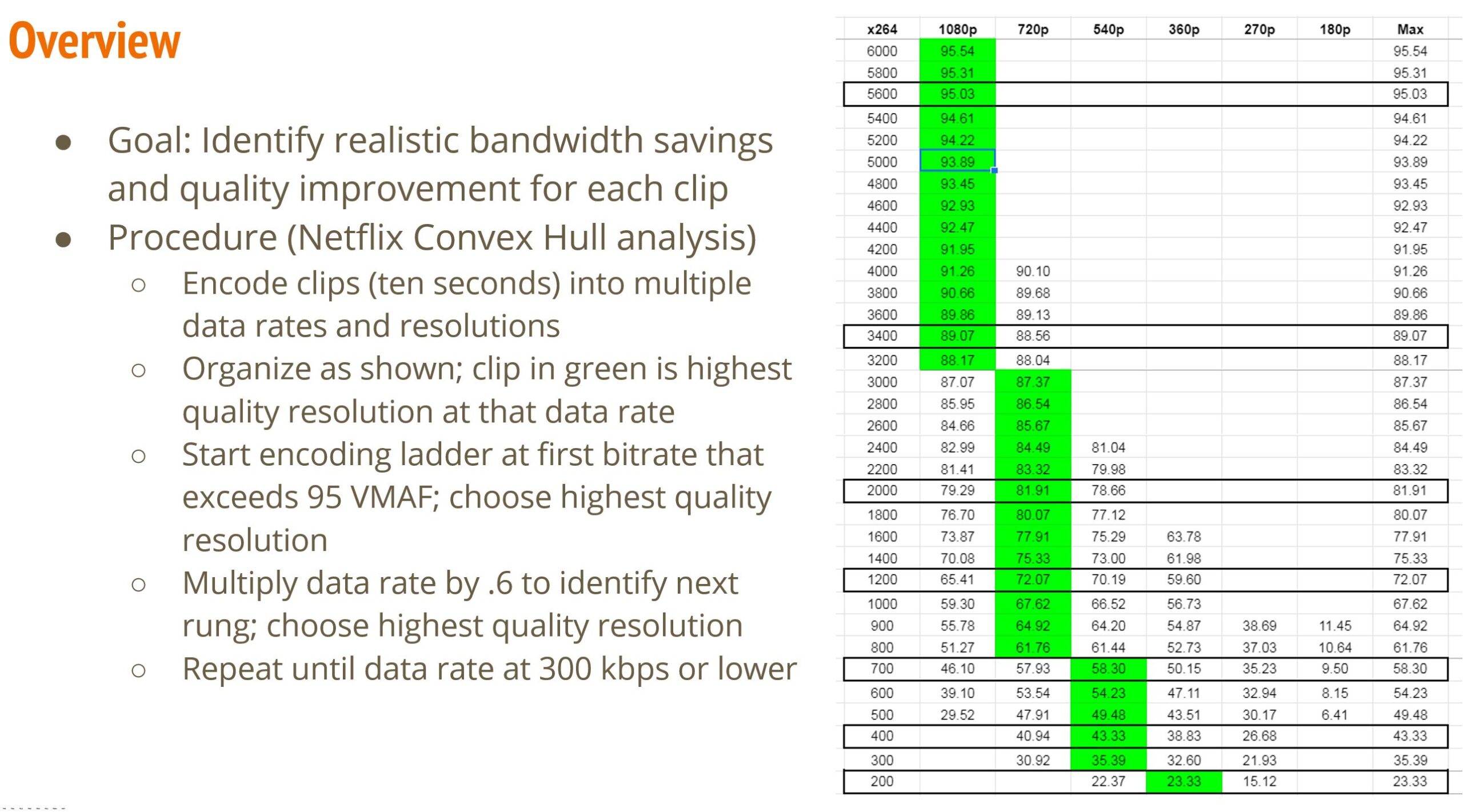
I decided to use a form of the Netflix convex hull technique explained here and here, and encoded each test clip about 200 times at different resolutions and data rates, and inserted the results into a spreadsheet like that above. Using conditional formatting in Google Sheets I highlighted the highest VMAF score for all the resolutions in each data rate rung.
To build the ladder, I chose the first rung at 95 VMAF points which is a good target for your top quality rung. That would be 5600 kbps in the clip above. Then I multiplied this rate by .6 to get the rate for the next rung on the ladder to achieve the desired spacing of between 1.5 – 2x between rungs (see here).
At each data rate, I choose the resolution with the highest VMAF score and rinsed and repeated until the data rate was under 300 kbps. Then I repeated the whole process for each codec to come up with comparable encoding ladders.
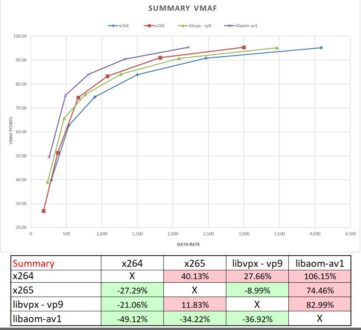
I tested ten-second segments from nine clips with this technique including the well-known test clips Tears of Steel, Sintel, Meridien, Football and Animals from Harmonic, a segment from the movie Zoolander, plus scenes from a music video, a hockey game, and a hideously hard to encode test clip called Carlot. To be clear, I performed this analysis four times for each test clip; once for each codec. I show the overall results below.
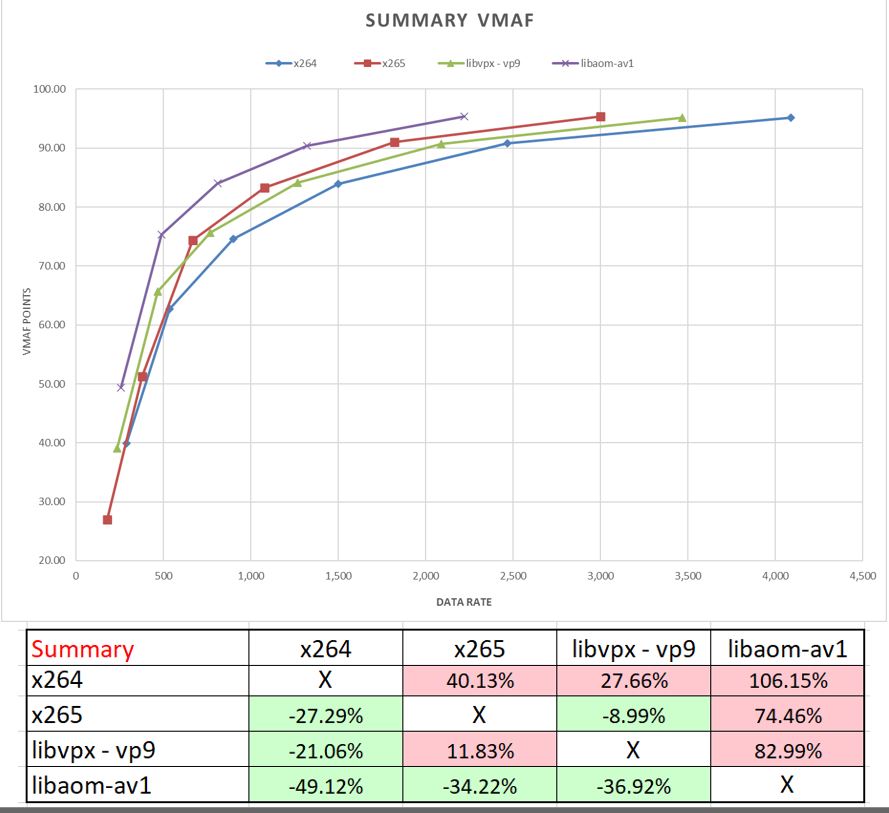
The curve shows that all ladders started around the 95 VMAF point mark, as designed, and that the purple libaom-AV1 was the star of the show. Interestingly, if you compare the green libvpx-vp9 and blue x265, you see that libvpx-vp9 saved only about 700 kbps at the top end with much of the performance benefit over H.264 and HEVC in the middle range. Overall, as shown in the BD-Rate stats, libvpx-vp9 could produce the same quality as x264, on average, at a bitrate reduction of 21.06%.

Computing Real-world Bandwidth Savings
how would this impact the average libvpx-vp9 implementor? Well, I hope you brought your bifocals (click the image above to load the full rez version).
The spreadsheet shows the same x264 ladder created by averaging the ladders from the nine test clips. It shows that ladder three times, with three distribution patterns in the highlighted red % column.
By distribution pattern, I mean the percentage of viewers who actually watched each rung. The first ladder is top-heavy, meaning that most viewers watched the top three rungs. The second is very top-heavy at 100% top rung, the third more middle-centric, as if distributing primarily to mobile devices. There’s nothing special about these distribution patterns; I just wanted to explore how different patterns impacted the results.
For each scenario, I multiplied the data rate and VMAF score by the percentage of each rung and then added up each column to compute the average bitrate and average VMAF score. To give credit where credit is due, this technique was suggested to me by Brightcove’s Yuriy Reznik and first implemented while creating this analysis of LCEVC technology with V-Nova’s Guendalina Cobianchi.
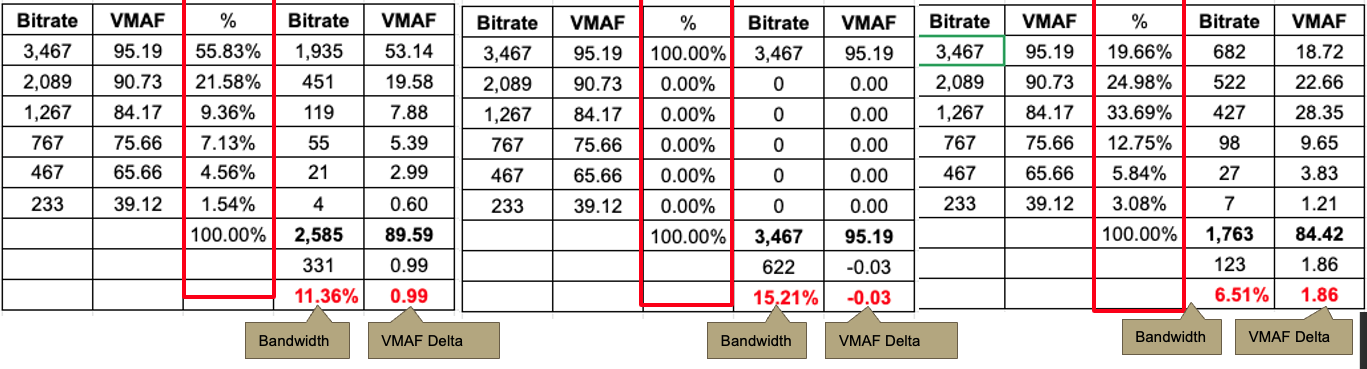
Then I applied these distribution patterns to libvpx-vp9, reallocating the bitrate to the rungs proportionately, and did the same math, computing the average bandwidth and VMAF score for libvpx-vp9 for each distribution pattern. Then I subtracted the libvpx-vp9 bandwidth and VMAF score from the H.264 score to identify the real-world bandwidth saving and VMAF uplift.
Then I did the same for x265 and libaom-AV1 and, to save your eyes and mine, present the summary results below. In scenario 1, libvpx-vp9 saved 11.4% bandwidth and boosted VMAF by .99. In the best case for bandwidth savings scenario 2, libvpx-vp9 reduced bandwidth by 15.2 with minimal change in VMAF. In the mobile-centric third scenario, libvpx-vp9 reduced bandwidth by 6.5% and boosted VMAF by 1.86.
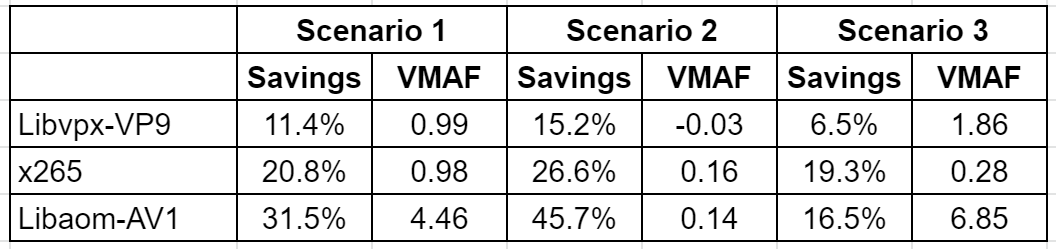
What happened to the BD-Rate savings of 21.06%? As I explain in the video (about 11:08 in), libvpx-vp9 is weak compared to x265 at the high end where most of the bandwidth savings exist and picked up most of its BD-Rate advantage at the lower end where bandwidth savings are minimal.
Most importantly, there are minimal bandwidth savings below the highest rung because the data rate differences between the rungs get smaller and might even reverse on some clips. Most of the savings are achieved in the differential between the top rungs in the encoding ladder.
libvpx-vp9 did poorly because its top rung performance was modest, well behind x265. In contrast, x265 saved more in the real-world analysis than the BD-Rate average because it performed well in the top rung, while its BD-Rate number was dragged down by poor performance in the lower rungs, where bandwidth losses are minimal.
Compatible Platforms Only
One aspect I didn’t include in this analysis relates to the fact that the new codec will only deliver bandwidth savings (and/or quality uplift) to compatible platforms that can actually play that codec. Since no codec can completely replace H.264 at this point, this means that bandwidth savings will only be realized on a subset of existing platforms.
With libvpx-vp9, that subset is large, incorporating most browser-based playback, plus iOS, Android, and many Smart TV and OTT platforms. With HEVC, the browser market is largely excluded though HEVC support is strong in mobile and the living room. In all cases, to produce an accurate estimate of bandwidth savings, multiply the bandwidth savings computed above by the percentage of existing players that support the new codec.
Summary
What’s this all mean? First, though libvpx-vp9’s BD-Rate numbers are encouraging, the real-world analysis tends to indicate that implementing libvpx-vp9 would deliver minimal bandwidth savings to all but the largest enterprises. There may be VP9 alternatives that deliver better quality, but I haven’t tested any.
The related point, of course, is that BD-Rate numbers can’t be used to estimate real-world savings. To be accurate there, you have to consider a full encoding ladder and actual distribution statistics.



Such a good article! Thanks for the analysis, I look forward to continuing with VP9 alternatives
Thanks, Andy, I’m glad you found it useful – thanks for taking the time to share.
Have a great day.
Jan