 Streaming Learning Center Where Streaming Professionals Learn to Excel
Streaming Learning Center Where Streaming Professionals Learn to Excel

Related Articles

Recently, I reviewed the Deep Render AI codec and noticed a substantial disconnect between subjective and objective results. Subjective testing showed Deep Render with a 45 percent BD-Rate advantage over SVT-AV1. VMAF showed just 3 percent. While subjective evaluation has always been the gold standard, this gap forced a more basic question: how accurate are traditional objective metrics when applied to AI-based codecs? What are the best video quality metrics for AI codecs?
As it turns out, this is well-traveled ground. Researchers evaluating both learned image and video compression have reached the same conclusion: conventional metrics often fail when applied to modern, AI-powered encoders.
This article looks at two studies that tackle the problem directly. The first evaluates JPEG AI against traditional codecs using formal subjective testing and fifteen different objective metrics. The second focuses on machine learning–based video compression and compares the performance of existing metrics to a new deep-learning-based alternative. Both papers offer concrete evidence that metrics like PSNR, MS-SSIM, and even VMAF break down in predictable ways when applied to neural codecs.
Along the way, we’ll also look at a proposed alternative, MLCVQA, in more detail, and consider what it would take to build a learned successor to VMAF. Finally, we’ll close with some practical recommendations for how to approach codec evaluation today, when subjective testing isn’t always feasible—and when “better than nothing” isn’t always good enough.
Contents
1. Subjective Visual Quality Assessment for High-Fidelity Learning-Based Image Compression
This study focused on evaluating learning-based image compression methods, particularly JPEG AI, which uses deep neural networks to reconstruct high-fidelity images. The researchers conducted formal subjective tests to assess how these methods compare to traditional codecs. Then they evaluated 15 objective image quality metrics to see how well each one predicted perceived quality across both traditional and AI-based outputs.
The results highlight a problem many codec developers already suspect: traditional metrics often do not capture the perceptual improvements or artifacts introduced by AI-based methods.
To measure the correlation between subjective and objective results, the researchers used two standard statistical tools:
- PLCC (Pearson Linear Correlation Coefficient): This measures how closely the metric tracks the actual subjective scores in a straight-line relationship. A value close to 1 means the metric accurately reflects differences in perceived quality.
- SRCC (Spearman Rank Correlation Coefficient): This measures how well the metric preserves the ranking of quality across different encodes. Again, higher values are better, with 1.0 indicating a perfect match to subjective rankings.
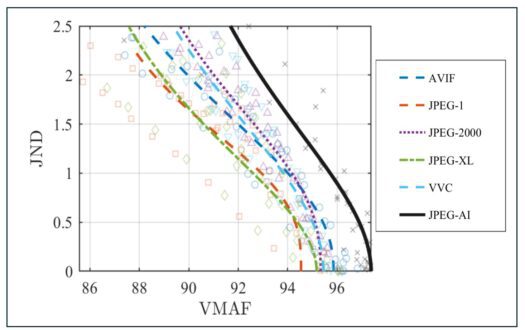
Now let’s look at the results. Table II of the paper summarizes how well each metric correlates with viewer scores in four different scenarios. The third column, labeled Per-codec SRCC, shows strong results. It averages the metric’s performance across all codecs, and the scores are uniformly high. VMAF hits 0.928, PSNR reaches 0.930, and MS-SSIM leads at 0.960. At first glance, this suggests that the metrics accurately assess visual quality.
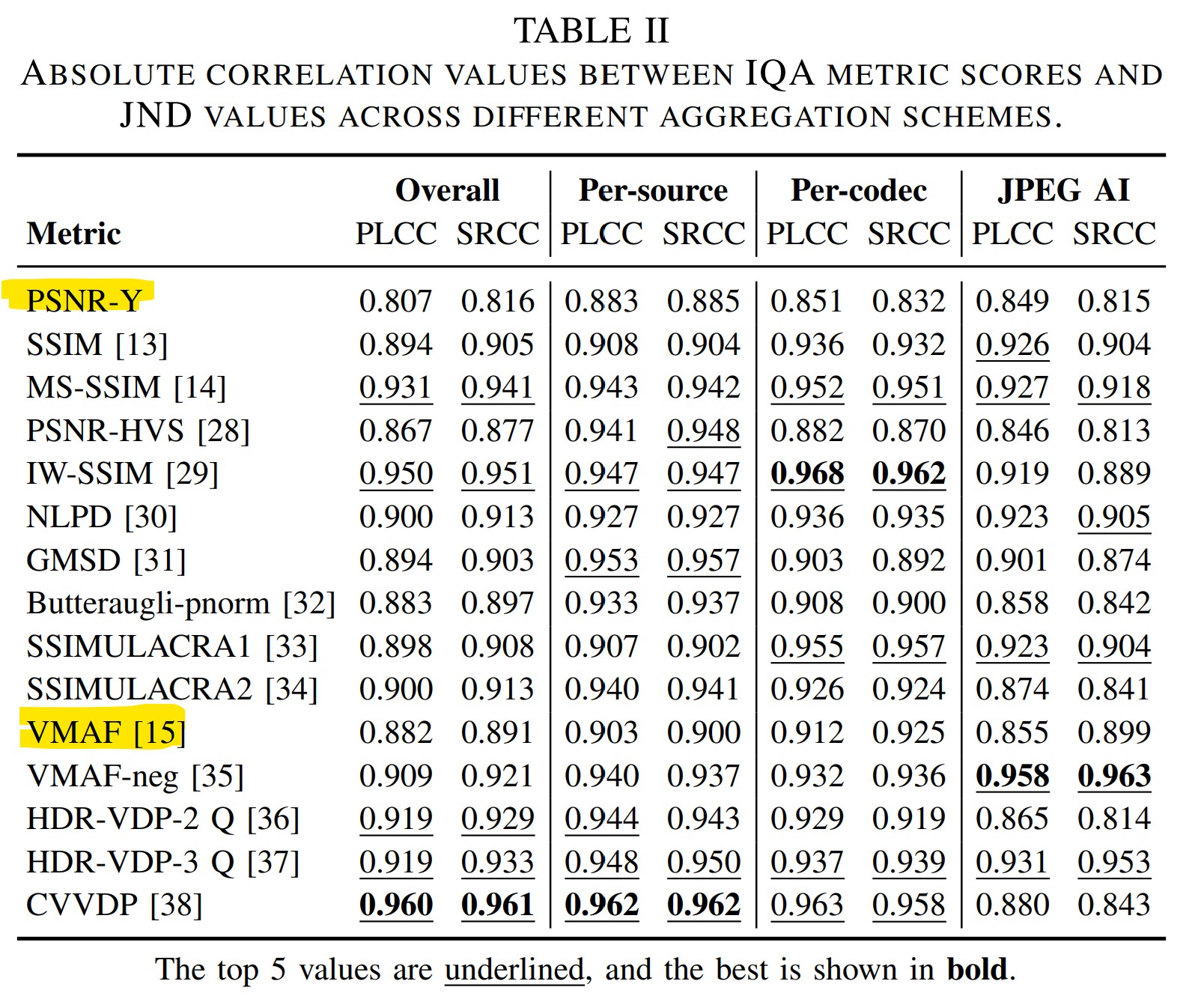
But the fourth column focuses on JPEG AI alone, and the numbers tell a different story. Every metric performs worse on this AI-based codec. VMAF drops to 0.899, PSNR to 0.859, and MS-SSIM to 0.941. These are not terrible scores, but they consistently underperform compared to the per-codec averages. This tells us that traditional metrics are less reliable when applied to learned compression methods like JPEG AI.
It is also important to remember that JPEG AI is included in the column 3 averages. That means the high correlation values in column 3 are already being pulled down by JPEG AI’s weaker performance. If the table had separated traditional codecs from neural ones, the contrast would likely have been even stronger. In other words, the actual drop in reliability between traditional and AI-based codecs is understated by this format.
A Surprising Outlier: VMAF-neg
While nearly every objective metric in the study performed worse on JPEG AI than on traditional codecs, two exceptions stand out. VMAF NEG and HDR-VDP-3 both delivered higher correlation scores on JPEG AI than they did across the full set of codecs. VMAF NEG saw the most significant gain, with its SRCC increasing from 0.936 to 0.963. HDR-VDP-3 improved more modestly, from 0.939 to 0.953.
VMAF NEG ‘s strong performance is especially noteworthy because it outscored every other metric tested. As you may know, VMAF NEG (for No Enhancement Gain) uses a neural network backend to penalize perceptual distortions that can trick traditional metrics, such as over-sharpening or structural hallucination. That may have made it more responsive to the perceptual changes JPEG AI introduced.
However, VMAF NEG was not trained on learned compression outputs and was never intended for this type of content. Its strong showing likely reflects a coincidental alignment between its bias correction strategies and the specific types of artifacts JPEG AI produces. The same is true of HDR-VDP-3, which was designed for high dynamic range video, not AI-based image compression.
These results are interesting but should not be interpreted as broad validation. Until these metrics are retrained on datasets that include learned compression, their role in evaluating AI codecs remains speculative.
From all this data, the authors concluded, “most metrics…were overly optimistic in predicting the quality of JPEG AI-compressed images. These findings emphasize the necessity for rigorous subjective evaluations in the development and benchmarking of modern image codecs, particularly in the high fidelity range.” This isn’t surprising, particularly as it relates to VMAF, as JPEG AI uses fundamentally different compression techniques than VMAF was trained on.
2. Full Reference Video Quality Assessment for Machine Learning-Based Video Codecs
This paper tests whether traditional full-reference quality metrics hold up when applied to machine learning–based video codecs. The answer is mostly no. The researchers built a new dataset from the CVPR 2022 CLIC video compression challenge, which included 810 clips encoded using 27 codec-bitrate combinations—some traditional, some learned. They collected subjective scores for each encoded clip using standardized methods (DCR, ACR, CCR). They compared those scores against predictions made by seven objective metrics, including PSNR, MS-SSIM, LPIPS, VMAF, and their own new model: MLCVQA.
The authors focus on both clip-level and model-level performance. Clip-level refers to how accurately the metric predicts the subjective quality of an individual encode. Model-level refers to how well the metric tracks the average subjective quality across all encodes from a given codec. Model-level performance is particularly relevant to codec development, where developers want to know how one codec performs relative to another—not just whether it produces occasional artifacts.
At the model level, the traditional metrics struggle. PSNR shows the weakest correlation to subjective opinion with a Tau-b 95 of just 0.82. Briefly, Tau-b is a rank correlation metric that measures how well a model preserves the order of subjective quality across items. The 95 variant incorporates uncertainty by treating scores as tied if they fall within each other’s 95 percent confidence intervals. A perfect score is 1.0, and scores above 0.90 are considered strong, while values below 0.85 suggest frequent misrankings. With PSNR at 0.82 and the dataset’s theoretical ceiling at 0.975, it’s clear that PSNR isn’t an accurate predictor of subjective results.
MS-SSIM performs slightly better but still falls short of the top-performing models. VMAF does reasonably well when retrained (more on this below), reaching a Tau-b 95 of 0.90, but even that lags behind the author’s MLCVQA model, which tops out at 0.93. Table 2 highlights where each model’s performance is statistically distinguishable from the top result, something rarely included in VQA research.
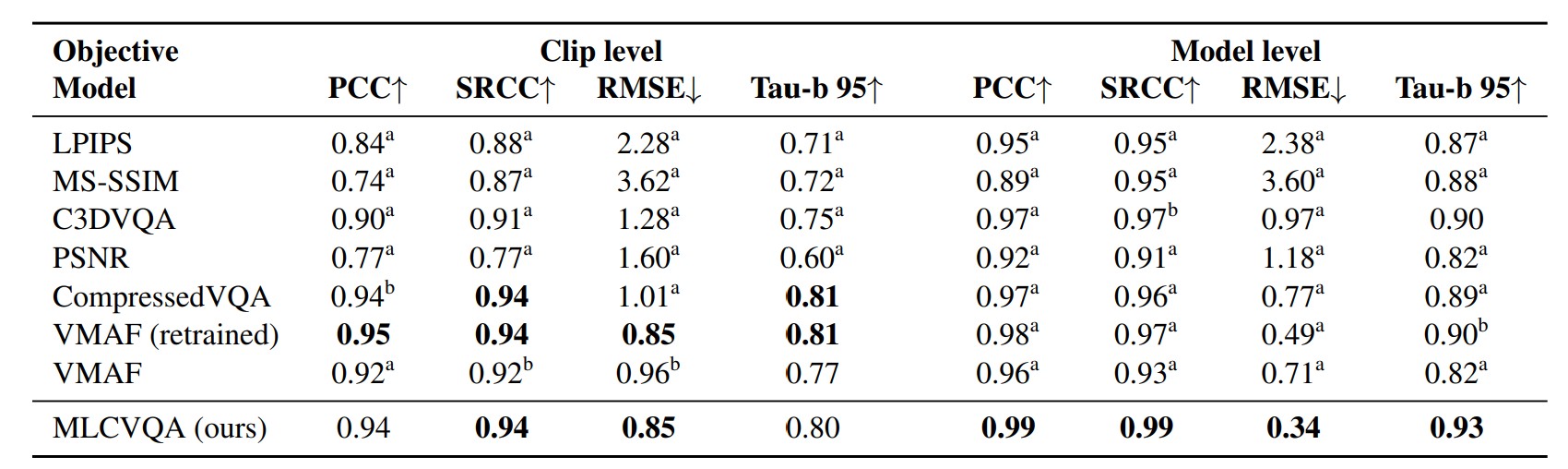
VMAF’s retrained performance improves over the baseline, but the paper does not specify how the retraining was performed. The authors state only that they retrained VMAF using the same data splits and augmentation strategies applied to their own model, but they do not provide details on whether they modified the SVR pipeline, the feature set, or the target labels. It’s unclear whether the improvement reflects deeper model tuning or simply a re-optimization of weights.
Even with retraining, VMAF and other metrics fail to track quality as reliably as MLCVQA. That becomes clear in Figure 1, which plots predicted vs. subjective scores for each metric at both the clip and model level. Briefly, the closer the scatter dots are to the diagonal center line, the more accurately they predict subjective ratings. At the model level (bottom row), MLCVQA’s predictions closely follow the diagonal, meaning it accurately captures the relative quality of different codecs. Traditional metrics like MS-SSIM and PSNR show much wider scatter and frequent misrankings.
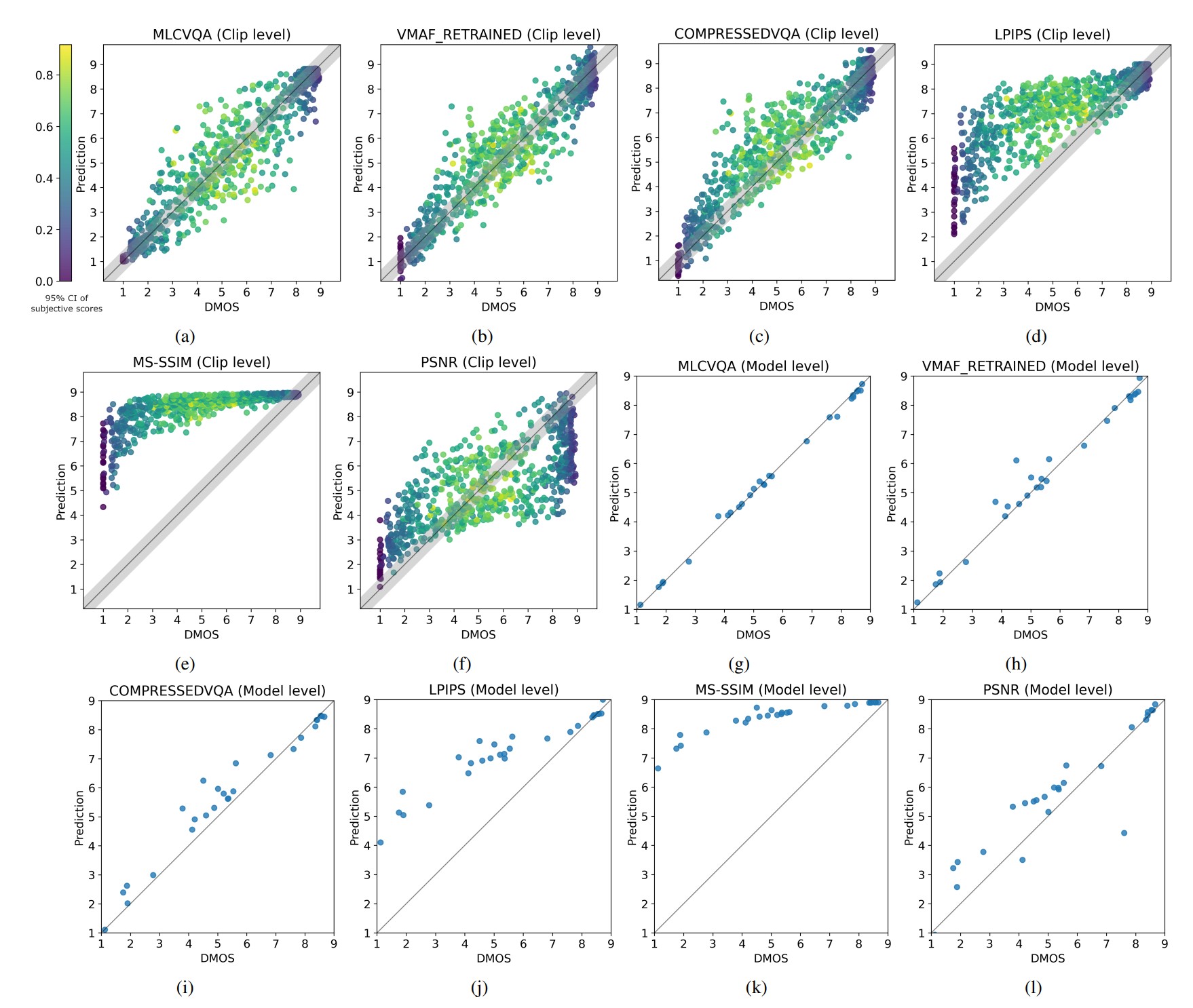
As mentioned above, the authors also introduce a lesser-known metric, Kendall’s Tau-b 95, as a more rigorous alternative to SRCC. Tau-b 95 incorporates uncertainty in subjective scores by treating two items as tied if their subjective scores fall within each other’s 95% confidence intervals. This makes it more robust in practice, especially when the number of raters is limited or when codec differences are small.
By emphasizing Tau-b 95, the authors make a broader point: ranking codecs based on metrics like VMAF may look statistically solid at a glance, but those rankings often don’t hold up when you account for rating uncertainty. This is especially important in the middle range of the quality spectrum, where subjective confidence intervals are widest and models tend to be least accurate.
As the authors summarize in the abstract, “We show that existing evaluation metrics that were designed and trained on DSP-based video codecs are not highly correlated to subjective opinion when used with ML video codecs due to the video artifacts being quite different between ML and video codecs.” Relating to VMAF, while retraining helps, it doesn’t solve the underlying problem that VMAF (and all the other metrics) were never designed to handle the artifacts, enhancements, or temporal dynamics introduced by neural networks.
Traditional video quality metrics like PSNR, MS-SSIM, and VMAF were never trained or designed to evaluate the kinds of distortions or enhancements introduced by learned video codecs. The JPEG AI study showed that these metrics consistently overestimate quality on neural compression methods. The Majeedi et al. paper extended that finding to video, demonstrating that even retrained versions of VMAF fall short when compared to a model specifically trained on ML-coded content.
These are not marginal differences. PSNR’s model-level Tau-b 95 was just 0.82, well below the dataset’s statistical ceiling of 0.975. MS-SSIM and baseline VMAF performed slightly better but still produced frequent misrankings. Even retrained VMAF, which reached 0.90, trailed the authors’ purpose-built MLCVQA model at 0.93. These results were not just visually compelling but statistically significant.
So, what should codec evaluators do today, knowing the tools they depend on are increasingly misaligned with the content they are testing? The short answer is to use multiple metrics and triangulate carefully. If VMAF, PSNR, and MS-SSIM all agree that Codec A outperforms Codec B, that may be useful directional data, but it does not guarantee accuracy. The studies above show that multiple metrics can agree and still be wrong in the same way. Just because a tool like PSNR or VMAF is accessible does not mean it is useful, and sometimes, “it’s better than nothing” simply isn’t.
Visual checks still matter, especially when metrics are likely to miss motion artifacts, detail hallucination, or temporal instability. While models like MLCVQA show what better evaluation could look like, they remain research tools for now. They require high-end GPUs and manual setup and have not yet been integrated into tools like FFmpeg or VQMT.
The bottom line is that until learned perceptual metrics become practical to run, or a next-generation VMAF emerges, AI codec evaluations that don’t include subjective testing will simply lack credibility.
Sidebar: MLCVQA – What a Learned Successor to VMAF Looks Like
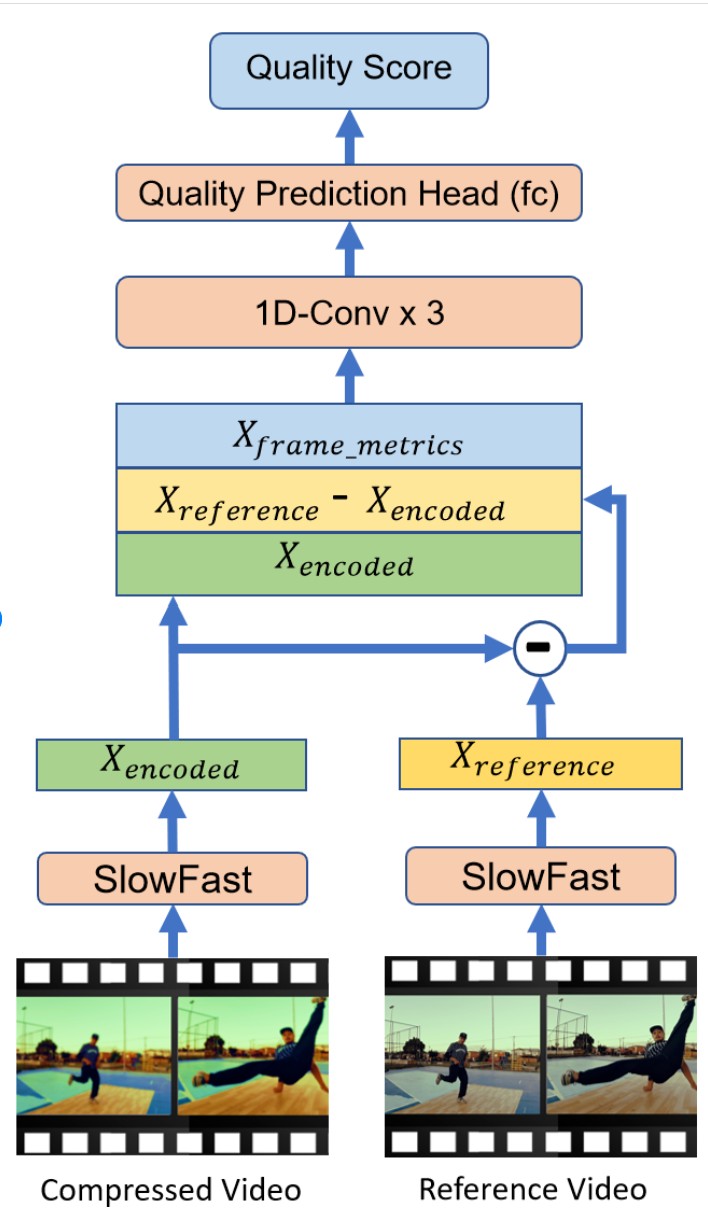
The central contribution of the Majeedi et al. paper is a new full-reference metric called MLCVQA, specifically designed to evaluate machine learning–based video codecs. Unlike traditional metrics like VMAF or PSNR, MLCVQA is trained on data from AI-coded videos using subjective scores as ground truth.
The model architecture combines deep features from a pretrained SlowFast network with pooled frame-level metrics such as VIF and DLM. These features are passed through a compact 1D convolutional network and a two-layer MLP to generate quality scores over time, which are then averaged to produce the final prediction.
The authors chose SlowFast because it preserves spatial resolution and chroma fidelity and captures temporal structure more effectively than earlier VQA models. This is critical for learned codecs, which often introduce motion-related artifacts that traditional metrics miss or misinterpret.
MLCVQA was trained using five-fold cross-validation and achieved a Tau-b 95 of 0.93 at the model level. This outperformed all other metrics tested, including a retrained version of VMAF (0.90), and showed better ranking fidelity across a wide range of content types and compression levels.
While the model, training code, and dataset are open source at https://github.com/microsoft/MLCVQA, practical use is limited. Training required eight NVIDIA V100 GPUs, and even inference relies on computationally intensive feature extraction using the SlowFast network. No optimized runtime or integration with tools like FFmpeg or MSU VQMT is currently available.
Still, the fact that retrained VMAF came so close to MLCVQA in model-level ranking accuracy suggests that VMAF’s basic structure, an interpretable regression model built on reliable features, may still have life left in it. What’s missing is a version trained natively on AI-coded outputs, using modern learned features in place of hand-crafted ones. A learned successor to VMAF, something like vmaf_ai, could retain the practical advantages of the current framework while dramatically improving alignment with perceptual quality. It may not be as far off as it sounds.



