Streaming Learning Center Where Streaming Professionals Learn to Excel
Streaming Learning Center Where Streaming Professionals Learn to Excel


Related Articles


The marketing story around vibe coding is awe-inspiring: a non‑programmer can describe any app they can imagine, and AI will do all the hard work. No code, no problem. Just vibes.
It turns out I was vibe coding before I ever heard the term. My goals were both less and more ambitious. Less ambitious, because I wasn’t trying to build the next unicorn app. More ambitious, because I wanted reliable tools that could automate real work in my video coding practice, not just a fun demo.
What’s the TL;DR? Vibe coding can do amazing things, but only if you evolve your toolset and delegation strategy. AI can be a great programmer, but is an awful project manager.
And be careful what you wish for; true software development is 5% fun and 95% grind. Vibe coding accelerates both components, but certainly doesn’t eliminate the latter.
Contents
Getting Started with Vibe Coding
When I was trying to understand what vibe coding was, I watched a video entitled, Tetris Transformed by AI: Vibe-Coding the Ultimate Block-Dropper! As the name suggests, the producer created a web version of Tetris via Vibe coding.
While this sounds incredible, this is a highly defined, limited-function task, which makes it simple for the AI to create. Real projects are never that clean, and videos like these, that get it right perfectly the first time, set expectations that reality can never quite meet.
For a dose of that reality, here’s a quick look at my vibe coding journey in three parts.
Take 1: Batch Files, Full Regens

Output: FFmpeg batch scripts, roughly 20–100 lines.
Code editor: Notepad++.
Creation schema: One simple prompt: “Write a batch file that runs these FFmpeg encodes with these parameters and compute VMAF with VQMT.”
Editing schema: If it didn’t work, I pasted the error into the chat and asked it to reproduce the entire script. No real debugging, just regenerate and hope.
The first stop on my journey was using AI to generate simple FFmpeg batch scripts.
I’d open Notepad++, describe what I wanted to ChatGPT, and let the model spit out a 20–100 line Windows or Linux batch file. If it didn’t work, I didn’t debug; I just asked for a new version of the whole thing and pasted it over the old one. Though crude, this method was simple and effective.
Take 2: Python, Surgical Replacements
Output: Python scripts, 100+ lines.
Code editor: Still Notepad++.
Creation schema: Product specs, design architecture reviews, and modules created by Vibe coding.
Editing schema: Paste errors into the AI and request targeted fixes. I attempted to train the AI to use the Find This / Do This method. Show me the code that needed fixing and provide the replacement code; I did this manually in Notepad++.

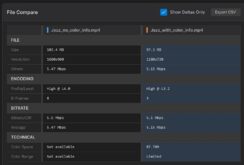
At this stage, architecture started to matter. The programs were doing real work, like finding the SVT-AV1 bitrate that yields a VMAF score of 93, and then creating a full encoding ladder using a convex-hull “lite” approach.
Or, start with an H.264 ladder, and then produce x265, VP9, and SVT-AV1 ladders that deliver the same quality at lower bitrates. Use these 20 files and report the overall performance of each codec by file and genre. Produce BD-Rate tables and RD curves using the correct aggregation approach. Definitely Python 101, but programs that could shave hours off a typical text cycle.

To accomplish an array of tasks, I created multiple command-line-driven apps that required common functions, like encoding to H.264 or measuring VMAF. So it made sense to break these functions out into separate modules that other programs could access.
Unlike a simple batch script for FFmpeg, real specs mattered, as did efficient and sustainable architectures. So, I created a spec > architecture review cycle from ChatGPT to Gemini, back and forth until the AI’s agreed.
Then the AIs, mostly ChatGPT, built the modules, but the editing cycle had to change. The programs now perform multiple functions and interface with other module and I needed to preserve their architectures and functionality while fixing bugs. So, rather than rewriting the entire program for each bug fix, I requested surgical find-and-replace updates, which I made manually.
As with any manual behavior, debugging was time-consuming and error-prone. In particular, Python is sensitive to indentation, so my pasting generated frequent errors. I had to stay on guard that ChatGPT, then Gemini, and ultimately Claude weren’t making unrequested “improvements” that deleted critical functions or hosed the interface with other modules.
As the programs got longer and more complex, this process became frustrating and exhausting. On multiple occasions, the LLMs took me through debugging loops that spiraled out of control, forcing me to revert to archived versions and costing me hours of work. I began to seriously question whether I could make any of these tools stable and complete enough for external use.
Take 3: Agentic Editing
Output: Multi-file Python project, up to ~1500 lines.
Code editor: Claude Code.
Creation schema: same.
Editing schema: Paste the errors into Claude Code, review the tool’s proposed changes, and let it apply edits directly across files instead of copy‑pasting chunks by hand.

By this point, the codebase is too large and intertwined for the old “copy this block into chat, paste back the fix” loop. I needed a tool that could view the entire project, propose coherent, surgical edits, and modify the files.
I pondered between Cursor and Claude Code, never really understanding the difference and how my seemingly debug-heavy workflow would translate. I liked working with Claude for coding and already had the subscription, but YouTube videos made Claude Code look like the DOS prompts I first wrestled with back in 1983.
I decided to go with the devil I knew, so I backed up all my .py files, held my nose, and installed Claude Code. 90 minutes later, I was totally hooked. I still paste errors into the DOS-looking black box, but Claude Code makes the changes directly into the individual programs, after I preview them, and is much more surgical about it than any general-purpose LLM. These auto‑applied changes are where everything flips.
For my kind of projects, that’s the real story. The important part of vibe coding isn’t that AI can conjure a script from nothing. It’s that it can sit in the messy 95%: debugging, tightening logic, and steadily improving tools you actually depend on.
If I had to do it all over again, I would have moved to Claude Code (or Cursor or another “Vibe coding” tool) once I transitioned from simple data-collection scripts to transcoding and analysis tools. If you can’t vibe code it with one simple request, get agentic help.
The Takeaway
Otherwise, I’ve got a gazillion takeaways from this process, but I’ll save most for another day and leave you with these.
The vibe coding schema that works exceptionally well for 100-line batch scripts is fundamentally unusable for longer, more complex projects. LLMs are like the proverbial drug dealer; they get you hooked on simple projects, giving you the confidence to tackle more complex projects that will certainly fail without changing your workflows.
At a much higher level, the thing that AI can’t do is think through all the requirements of your program and maintain its focus. It doesn’t know that your VMAF score must match that produced by other tools, that no one uses the placebo preset, or any of the thousands of details that make a program effective for real-world users.
In the context of producing real programs for real uses, AI is an amazing programmer, but a mediocre product planner, and an awful project manager. Delegate the wrong tasks to AI at your own peril.