Streaming Learning Center Where Streaming Professionals Learn to Excel
Streaming Learning Center Where Streaming Professionals Learn to Excel

Related Articles


Adaptive streaming technologies like Adobe’s Dynamic Streaming, Microsoft’s Smooth Streaming, and Apple’s HTTP Live Streaming, use multiple encoded files to deliver the optimal viewing experience to video consumers watching on a range of devices, from mobile phone to workstation, via a range of connections, from FIOS to cellular. Though there are differences in implementation, all adaptive technologies switch streams based upon heuristics like CPU utilization or buffer size. That is, if the player detects that buffer levels are too low, it may choose a lower data rate stream to avoid running out of data. If CPU utilization gets too high and frames start dropping, it may request a lower resolution file that’s easier to decode.
While most of the technology that enables stream switching is lodged in the player or streaming server, there’s lots to do on the encoding side to produce streams that switch smoothly. In this article, I’ll outline the key differences between producing for single stream delivery and producing for adaptive streaming.
Contents
High Level Decisions
Before starting on encoding-related decisions, let’s touch on some high-level configuration-related decisions, including the number of streams to distribute and their respective configurations. I covered these subjects in detail in an article entitled “Adaptive Streaming in the Field,” which you can find at http://bit.ly/ozeradaptive, which includes real world input from a diverse range of actual producers, from MTV to Harvard University.
In terms of the number of streams, entertainment-oriented sites produced the largest number of streams, with MTV and NBC at eight, while corporations and universities produced fewer. If the motivation behind implementing adaptive streaming is entertainment, err on the high-side; if utilitarian, you can produce fewer streams.
Regarding stream configuration, the biggest question is whether to produce all streams at the same resolution, or to vary stream resolution along with data rate. There are several items to consider here, including the resolution of the source, the display size(s) on the web page and the range of supported platforms.
For example, if you’re encoding an SD source file for display at a single display resolution, consider encoding all streams to that resolution and modifying data rate and perhaps frame rate in the various streams. Alternatively, if you’re encoding an HD stream for display at multiple windows sizes, consider producing files at multiple resolutions that match the display windows, an approach favored by MTV. If you’re producing adaptively for iOS devices, you’ll want to change resolutions for streams viewed on smaller, older iPod/iPhone/iPod touch devices and streams for playback on iPads.
Configuring Key Frames
Now let’s focus on how encoding for adaptive streaming differs from encoding for single-file distribution, starting with key frames, which are also called I-frames. Briefly, I-frames start each group of pictures (GOP) and are encoded solely via intra-frame technologies like JPEG, which makes them the highest quality but least efficient frame from a compression perspective. For single file streaming, I generally recommend one I-frame every ten seconds, with scene change detection enabled to insert key frames at scene changes to maximize quality.
When producing for adaptive streaming, you want shorter I-frame intervals because adaptive technologies can only switch streams at an I-frame, and ten seconds is a long time to wait to switch streams when your buffer is running low. Most producers use an interval of between two to five seconds. You want to deliver your video in regular-sized chunks, so you should disable scene change detection.
Finally, for technologies that distribute via chunks of data that may include multiple GOPs, like Apple’s HTTP Live Streaming, make sure that your key frame interval divides evenly into your chunk size. For example, if each chunk contains ten seconds of data, use a key frame interval of two or five.
Configuring Audio
If you’ve never seen adaptive streaming in action, it’s pretty impressive, with streams switching so smoothly that most viewers won’t ever notice. One major clue that something is happening, however, is when audio pops or warbles upon a stream switch. To avoid this, many producers use the same audio configuration for all files. If you’re broadcasting the news or a sporting event, this isn’t a big deal, but this may sound too restrictive for concerts, ballets or other events where sound is a bigger component of the overall experience.
Many producers that contributed to the aforementioned article did vary the audio configurations within their various files. To minimize potential issues, most used the same frequency for all streams and switched the number of channels, data rate or both. For example, consider using 44.1 kHz mono audio at 32 kbps for your lowest stream, 44.1 khz mono at 64 kbps for mid-quality streams and 44.1 kHz stereo at 128 kbps for your highest quality streams. Then test before going live to ensure that audio artifacts don’t occur when switching streams.
Bitrate Control – VBR or CBR
The most perplexing issue facing adaptive producers is bitrate control. As you know, there are two approaches, constant bit rate (CBR) encoding and variable bit rate (VBR) encoding. Briefly, CBR applies a consistent data rate over the entire file, while VBR varies the data rate according to encoding complexity, applying less data to easy-to-encode sequences, and more data to harder-to-encode sequences. This produces overall better quality, but also variability in the stream data rate. When distributing a single file, stream variability typically doesn’t cause any problems, so the extra quality makes VBR the preferred approach.
With adaptive streaming, however, excessive stream variability can artificially trigger unnecessary stream switching. For example, hard-to-encode scenes require more data which takes longer for the player to retrieve. While waiting to receive the data, the buffer could drop to an unacceptable level, triggering a stream switch that would not have occurred with a file encoded using CBR.
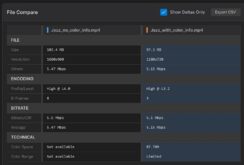
For this reason, CBR is considered the conservative, safe option for adaptive streaming. However, as shown in Figure 1, CBR quality (on the left) can be noticeably worse than VBR. This scene looks static, but is just three frames after a cross-dissolve transition. As analyzed in Inlet Semaphore, when producing the VBR stream on the right, the encoding tool (Sorenson Squeeze) allocated 7 KB to this frame, and looks great. On the left, in the CBR stream, Squeeze allocated only 1 KB to the frame, and it looks awful. On the other hand, as you can see in the data rate graph beneath the frames, the VBR stream is much more variable and inconsistent.

Figure 1. VBR on the right, CBR on the left. Click the figure to full a full resolution version.
How to avoid this drop in quality without risking too many stream switches? Use constrained VBR to limit the maximum data rate to a certain level above the target. For example, in Figure 2, I’m limiting the maximum data rate to 150% of the target in the file. This gives the encoder some wiggle room to boost quality while minimizing unnecessary stream switches. When producing VBR files for adaptive streaming, you should always constrain the stream bitrate to at most 200% of the target, perhaps as low as 110%.

Figure 2. Constrained VBR in Sorenson Squeeze.
Some producers use a hybrid approach, deploying CBR in the lower bitrate streams that are typically bunched more closely together, and constrained VBR in higher bitrate streams that are farther apart. This avoids artificial stream switches at both ends while enabling optimum quality at the high end of the spectrum.