Streaming Learning Center Where Streaming Professionals Learn to Excel
Streaming Learning Center Where Streaming Professionals Learn to Excel

Related Articles


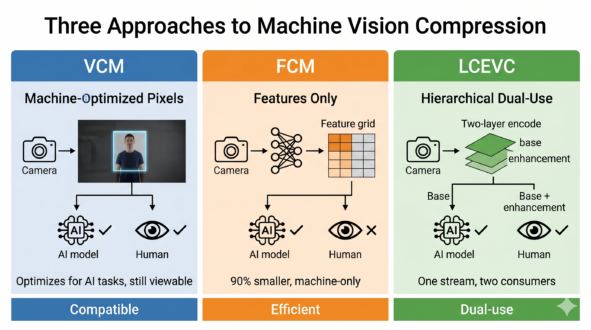
Video is increasingly captured primarily or exclusively for machine viewing, including applications like surveillance cameras, autonomous vehicles, industrial inspection, and drone footage. Traditional codecs like H.264 and HEVC were designed around human perception rather than machine vision tasks, which has opened the door to new compression approaches tailored to AI-driven workflows. Three emerging standards tackle this challenge from different angles: MPEG’s Video Coding for Machines (VCM), MPEG’s Feature Coding for Machines (FCM), and V-Nova’s LCEVC. Yes, LCEVC.
Contents
Video Coding for Machines
Video Coding for Machines, or VCM, is currently moving through the final ballot stages of the MPEG-AI roadmap as an upcoming international standard (ISO/IEC 23888-2). Operationally, it keeps video in the pixel domain but changes the optimization target. Operationally, it keeps video in the pixel domain but changes the optimization target. Instead of preserving what looks best to the eye, VCM attempts to preserve what helps computer vision models perform tasks such as detection, tracking, and classification. In practical terms, that can mean allocating more bits to objects or regions important to the model and fewer to background areas with minimal impact on task accuracy, using techniques like region-of-interest encoding.
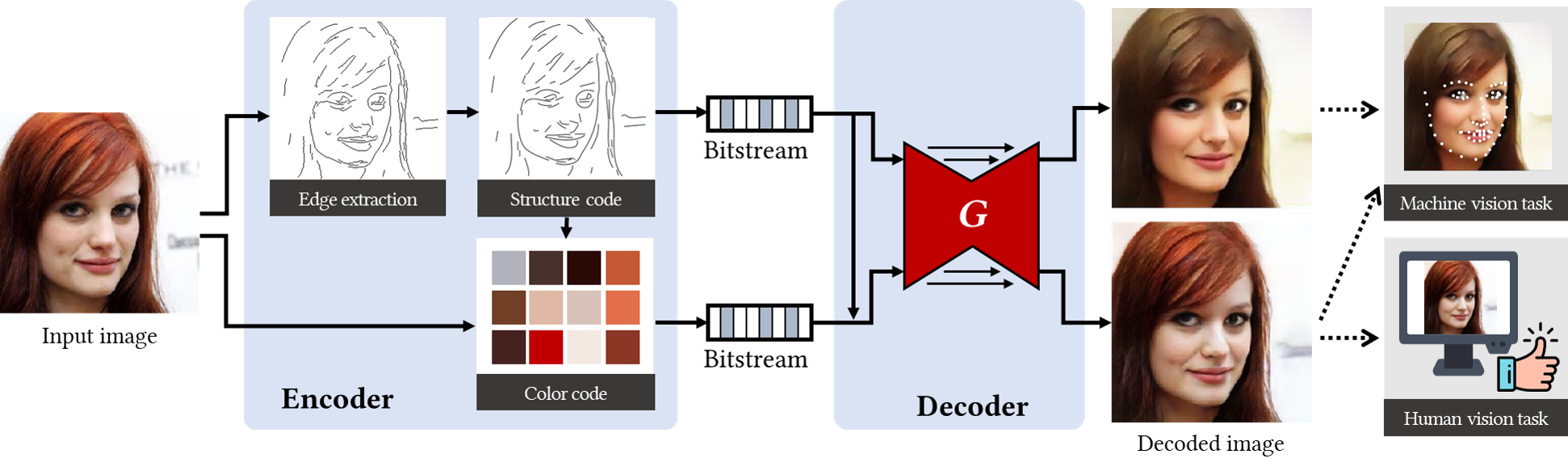
This is shown in Figure 1 (from here), which illustrates how VCM encodes image features optimized for machine tasks (edge extraction, structure coding, and color coding) while still producing a decodable bitstream. The same decoded output serves both a machine vision task (such as facial landmark detection) and conventional human viewing, demonstrating VCM’s dual-use architecture. However, a key caveat is that while the pixels remain available for human review or auditing, heavily optimized VCM streams will often appear distorted, blocky, or visually jarring to human eyes.
Feature Coding for Machines
While VCM is nearing the end of its standardization pipeline as a Draft International Standard, Feature Coding for Machines, or FCM (ISO/IEC 23888-4), represents a newer, more radical track on the same MPEG-AI roadmap, currently sitting at the Working Draft stage.. Instead of transmitting compressed pixels, it transmits compressed features extracted by a neural network, so the receiving system gets machine-ready data rather than a viewable picture. That makes FCM a machine-only approach by design: highly efficient when no one needs to monitor the stream, but not suitable when operators, auditors, or consumers also require conventional video output.

Figure 2 contrasts the traditional video pipeline with the FCM approach. In the traditional workflow (a), the mobile device encodes raw video, transmits the compressed bitstream, and the server decodes it back to pixels before running the full CNN for object detection (identifying the car at 100% confidence). In the FCM workflow (b), the mobile device runs the first portion of the neural network (NN Part 1) on the raw video, extracting intermediate features that the FCM encoder compresses. The server receives this compressed feature bitstream, decodes it, and runs only the second portion of the neural network (NN Part 2) to complete the detection task. By transmitting neural network features instead of pixels, FCM eliminates the decode-to-pixels step entirely and achieves substantially lower bitrates.
LCEVC – Base Layer for Machines; Enhancement Layer for Humans
V-Nova’s LCEVC is fundamentally different. It uses a hierarchical structure with a lower-resolution base layer produced using a traditional codec such as H.264, HEVC, or AV1, and an enhancement layer that fills in the details. If played back on a device without an LCEVC decoder, only the base layer plays at the lower resolution. When an LCEVC player exists, the video plays at full resolution. This architecture allows AI systems to work from the lower-resolution base while humans can still reconstruct the full stream, enabling a single encoded asset to support both machine analysis and human viewing.
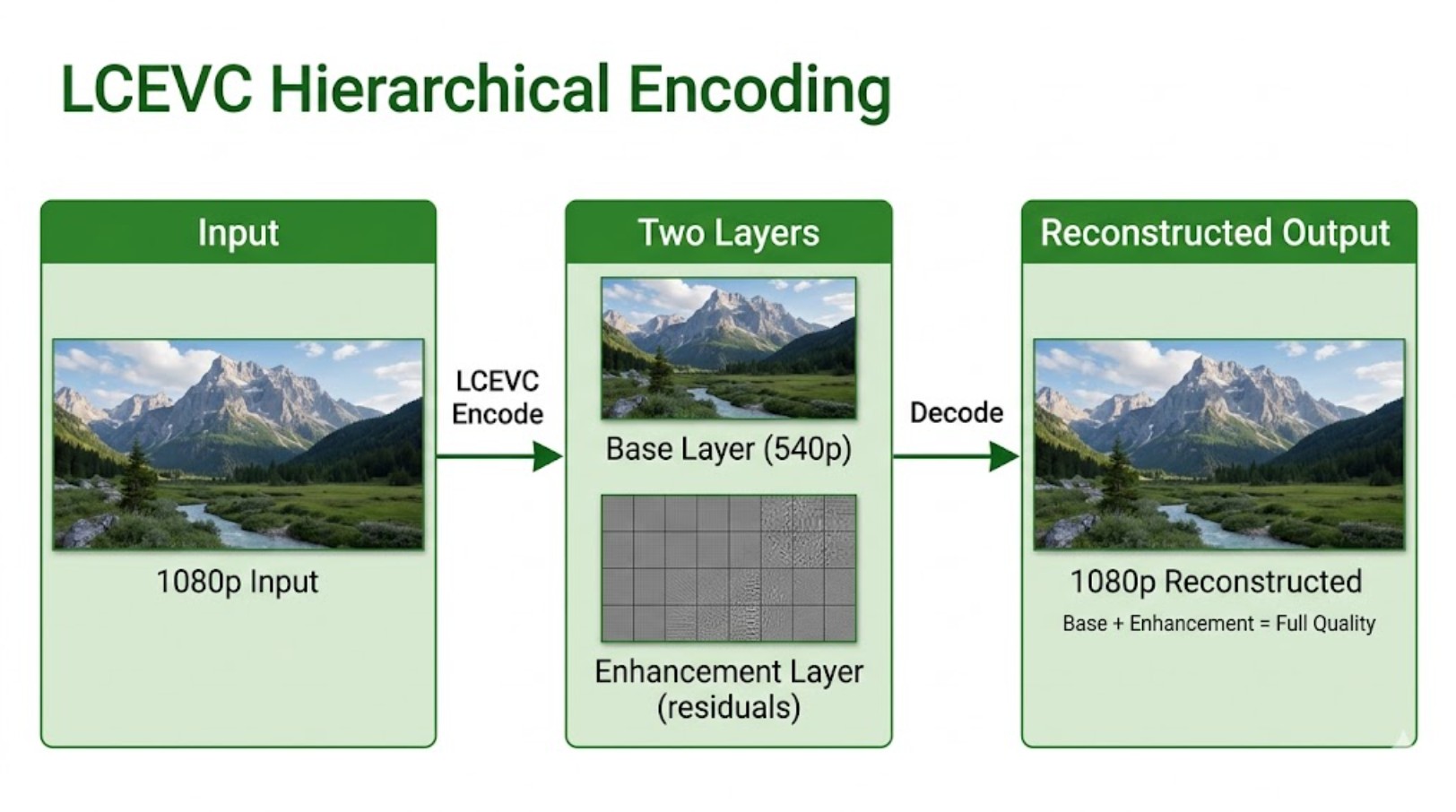
Figure 3 illustrates LCEVC’s hierarchical encoding structure. The encoder splits the 1080p input into two components: a base layer at reduced resolution (540p) that contains a decodable version of the scene, and an enhancement layer that stores the residual information needed to reconstruct full quality. AI systems can decode only the base layer for inference tasks, avoiding the computational cost of full-resolution decode, while human viewers can decode both layers to reconstruct the original 1080p output.
Note that working with the lower-resolution base layer for AI functions isn’t a disadvantage. Most AI vision models operate at significantly lower resolutions than the video content human viewers consume. Popular object detection models like YOLO typically process inputs at 640×640 pixels or smaller, while image classification networks such as ResNet commonly use 224×224 pixel inputs. Even advanced models rarely exceed 1024×1024 resolution due to the quadratic scaling of computational costs with image dimensions.
LCEVC’s dual architecture distinguishes LCEVC from both MPEG tracks. VCM is still fundamentally about machine-optimized video, and FCM is about machine-only feature transport, while LCEVC is being pitched as a practical bridge between the two worlds. V-Nova’s public case is that many real deployments don’t want to choose between a stream for AI and a separate stream for people; they want one workflow that can serve both.
LCEVC Performance Testing
The company also backs that argument with public test claims. In a joint evaluation with Intel using UHD traffic surveillance footage, Intel Deep Learning Streamer, and MobileNet SSD, V-Nova says decoding only the LCEVC base layer reduced combined decode-and-analytics time on CPUs by 30 to 50 percent and increased integrated GPU inference throughput by about 3×, while holding detection accuracy essentially steady. Those are V-Nova’s numbers, but they at least give the argument something more concrete than a generic “AI-ready” claim.
Those performance gains are modest compared to FCM. Rather than encoding pixels, FCM compresses the intermediate feature maps extracted by neural networks, transmitting only the task-relevant data needed for inference. In standardized testing, FCM achieved a 90% bitrate reduction versus H.264 and a 67% reduction versus VVC while maintaining equivalent object detection accuracy. That translates to roughly 10% of H.264’s bandwidth and 33% of VVC’s bandwidth for machine vision tasks.
However, FCM’s architecture requires compatible AI models on both ends and produces streams that can’t be decoded for human viewing, the compressed features aren’t interpretable as images. LCEVC’s more conservative gains preserve compatibility with existing codecs and dual-use scenarios in which both humans and machines consume the same stream, but at the cost of substantially lower compression efficiency in pure machine-vision workflows.
Summing Up
For now, the cleanest way to think about the landscape is this: VCM keeps pixels but tunes them for machine tasks, FCM skips pixels and sends features, and LCEVC keeps video viewable while letting machines work from the lower-resolution layer. All three start from the same premise: that a growing share of video is no longer compressed primarily for human eyes.
The open question is which compromise the market wants. If the workflow is machine-only, FCM has the clearest logic, delivering massive bandwidth savings that justify the infrastructure investment. If compatibility with existing video infrastructure matters most, VCM is the more natural path: it requires no AI processing at the origination point, works with standard video codec technology, and fits into current encoding workflows. If the real-world requirement is one encode for both AI and human viewing, V-Nova has planted itself squarely in that lane.