Streaming Learning Center Where Streaming Professionals Learn to Excel
Streaming Learning Center Where Streaming Professionals Learn to Excel

Related Articles


The white paper titled “Sandwiched Compression: Repurposing Standard Codecs with Neural Network Wrappers” is authored by a team from Google Research, including notable contributors such as Onur G. Guleryuz, Philip A. Chou, Berivan Isik, Hugues Hoppe, Danhang Tang, Ruofei Du, Jonathan Taylor, Philip Davidson, and Sean Fanello. Their collective expertise in image and video processing, neural networks, and rate-distortion optimization lends significant credibility to the paper. The authors are recognized figures in the field, with established research contributions and affiliations that enhance the paper’s authority.
This research addresses a fundamental challenge in image and video compression: the performance gap between traditional codecs (e.g., JPEG, HEVC) and neural codecs. While neural codecs demonstrate superior rate-distortion performance, they require considerable computational resources, making them impractical for real-time applications on mobile devices or UHD graphics rates. The Sandwiched Compression approach seeks to bridge this gap by leveraging pre- and post-processing neural networks around standard codecs. This innovation not only enhances the performance of traditional codecs but also adapts them to non-traditional content types and distortion measures.
Contents
The Big Idea
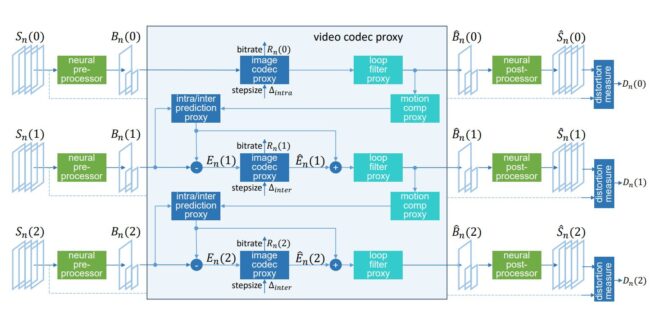
Sandwiched Compression wraps traditional codecs (like HEVC) between neural networks to enhance compression efficiency and perceptual quality while staying compatible with existing playback systems. The neural networks act as:
- Pre-Processor: Transforms the input (video) to compress better with the traditional codec.
- Post-Processor: Reconstructs the output, enhancing quality and reversing artifacts.
The goal is to combine the best of both worlds: the efficiency of traditional codecs with the rate-distortion performance of neural networks. This approach is especially innovative because it aims to repurpose standard codecs for tasks they weren’t designed for, such as:
- Color over Grayscale: Encoding full-color video using HEVC 4:0:0 grayscale.
- Super-Resolution: Encoding at lower resolutions and upscaling with neural networks.
- Perceptual Optimization: Using LPIPS and VMAF to reduce bitrate while maintaining subjective quality.
However, the paper focuses heavily on HEVC 4:4:4, which is almost never used in streaming, and relies on LPIPS PSNR, a non-standard metric. This makes it difficult to assess real-world impact.
How It Works
Sandwiched Compression wraps traditional codecs (like HEVC) between neural networks. Here’s how it works:
- Pre-Processor: Transforms the video input to compress better with the traditional codec.
- Post-Processor: Reconstructs the output, enhancing quality and reversing artifacts.
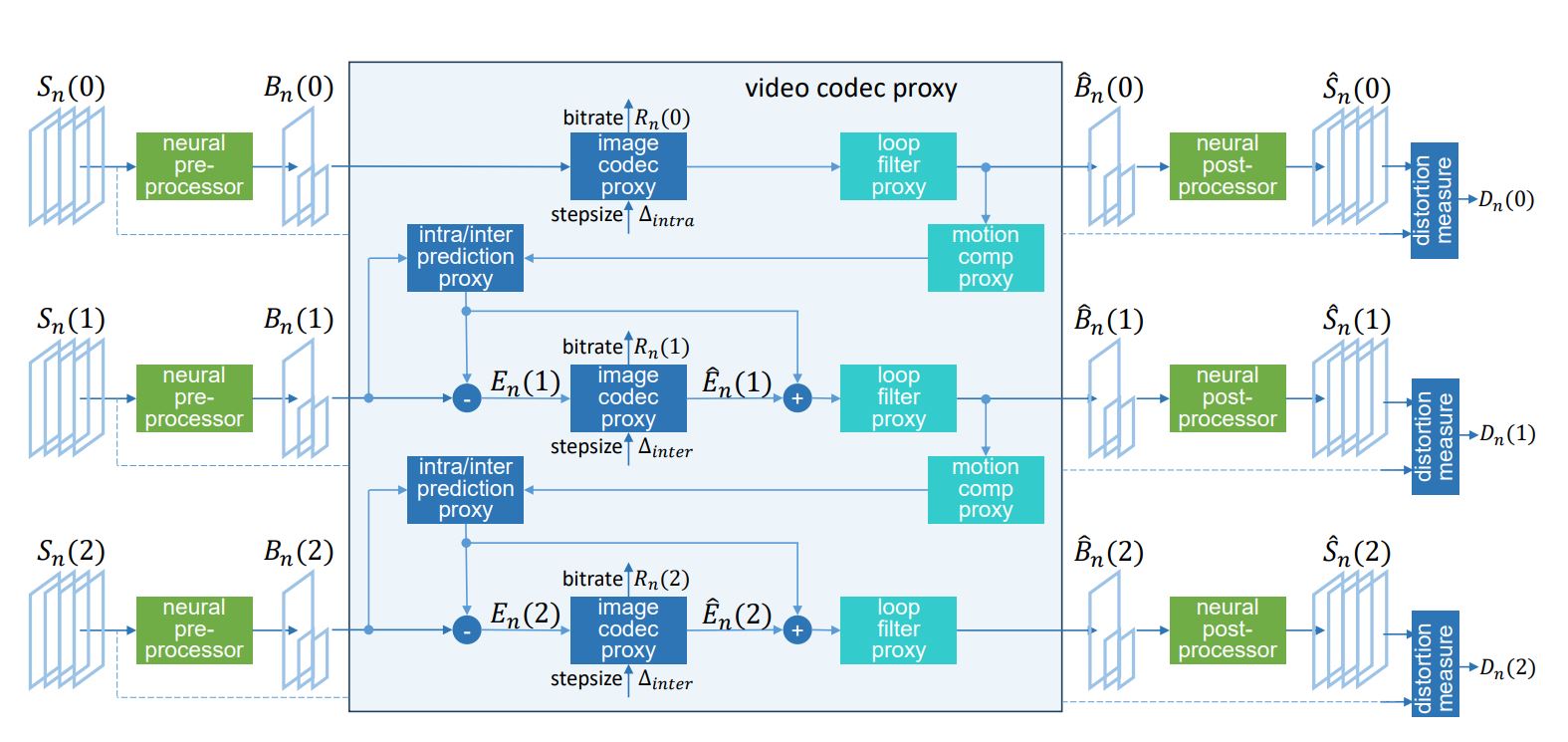
One of the core innovations is the use of a Differentiable Codec Proxy. During training, this proxy replaces the standard codec, allowing backpropagation through the entire neural sandwich architecture. It uses a quantization scaling factor and a rounding function to simulate the effects of quantization, enabling gradient-based optimization. This is crucial for jointly training the pre- and post-processors without modifying the codec itself, maintaining compatibility while optimizing rate-distortion performance.
The neural networks primarily use U-Nets with varying parameter counts to balance complexity and performance. They experimented with slim and full versions, ranging from 57K to 7.8M parameters, showing good scalability while preserving most of the performance gains. This balance is key to achieving real-time processing on high-end GPUs.
Training Process
The neural networks are trained using a combination of LPIPS and VMAF as perceptual loss functions, optimizing for both pixel-level accuracy and perceptual quality. The training involves large-scale datasets, including the AOM Common Test Conditions for video compression. They used a multi-objective loss function to balance rate-distortion trade-offs, with joint optimization of the pre- and post-processors.
Blind Version
The paper also proposes a “blind version” of the sandwich architecture, where the post-processor does not have access to the original input. This version relies entirely on the neural codes transmitted through the standard codec. This design choice has implications for practical deployment, as it avoids the need for storing or referencing the original video, making it more feasible for real-world streaming scenarios.
Performance and Results
Color over Grayscale
- What It Does: Encodes full-color video using HEVC 4:0:0 grayscale, then reconstructs the color with neural networks.
- Claimed Gains: 8.5 dB PSNR improvement over standard grayscale HEVC.
- The Catch: This is a niche use case meant for backward compatibility or ultra-low-bandwidth channels where only grayscale is supported. It’s not practical for most streaming scenarios.
Super-Resolution
- What It Does: It compresses lower-resolution video and uses neural networks to upscale and reconstruct the high-res version.
- Claimed Gains: 6+ dB PSNR improvement over traditional upscaling methods.
- The Catch: This requires high GPU power for the neural post-processor and doesn’t outperform modern AI-based super-resolution methods that can be applied after decoding without changing the codec.
Perceptual Optimization
- What It Does: Uses LPIPS to optimize for perceptual quality, claiming a 30% bitrate reduction at the same perceptual quality level.
- Pre-only HEVC: Shows 10% bitrate savings while staying fully compatible with existing HEVC decoders.
- The Catch:
- Most testing was conducted on 4:4:4 HEVC, but they did perform some experiments on YUV 4:2:0 videos with mixed results. The 4:2:0 tests showed lower perceptual gains, suggesting that the technique is less effective in the more common streaming format.
- They mentioned using VMAF during training, but the paper presents little VMAF data, making it difficult to fully verify the claimed bitrate savings.
Key Figures
- Figure 1: Shows the architecture of the Sandwiched Compression system with pre- and post-processors wrapping the HEVC codec.
- Figure 2: R-D curve for the pre-only HEVC setup, claiming 10% bitrate savings. But it’s only tested in 4:4:4 HEVC using LPIPS PSNR, and no VMAF RD curves are shown.
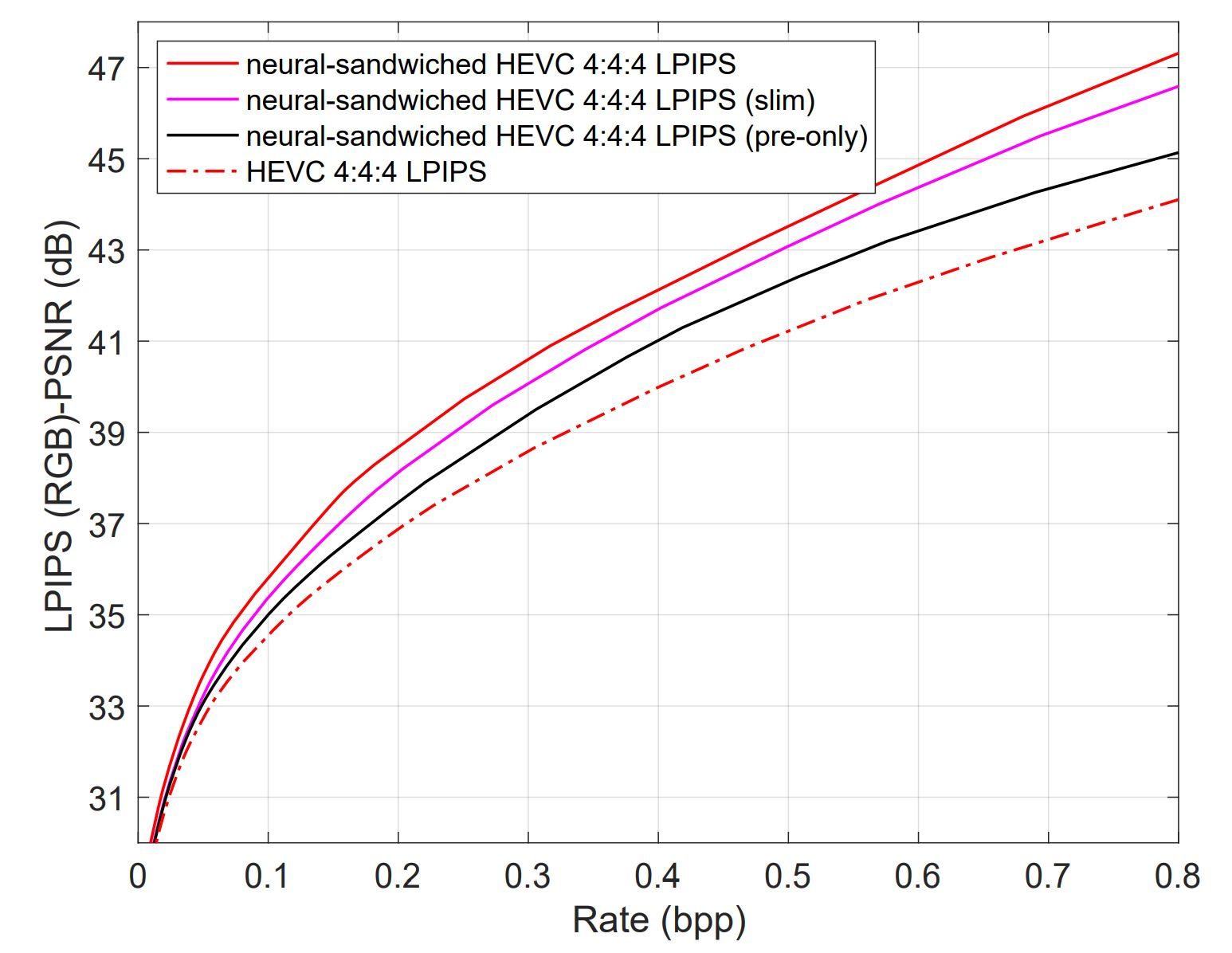
- No VMAF RD curves were presented, despite claims of VMAF improvements. This raises serious questions about the validity of the claimed bitrate savings.
What’s Challenging
- Niche Use Cases: The most innovative scenarios (color over grayscale and super-resolution) are for specialized graphics workflows or legacy systems, not mainstream streaming. The paper positions these as solutions for backward compatibility or ultra-low-bandwidth channels, which are valid but niche applications.
- Questionable Testing Choices: They focused mainly on HEVC 4:4:4, which isn’t used in consumer streaming. However, they did conduct some experiments on 4:2:0 videos, but the results were mixed, showing lower perceptual gains.
- No Subjective Tests: All quality claims are based on LPIPS and VMAF metrics, with no human subjective testing to confirm perceived quality. The paper defends the use of LPIPS for perceptual optimization but acknowledges the lack of subjective validation.
- Missing VMAF RD Curves: They mentioned using VMAF during training and showed related VMAF results, but they didn’t provide full VMAF RD curves. This makes it difficult to fully verify the claimed 10% bitrate savings for real-world perceptual quality.
Bottom Line
- Innovative but Impractical: The architecture is technically innovative, but the testing choices are so niche and unrealistic that it’s hard to see any real-world application. The paper’s focus on 4:4:4 HEVC and LPIPS PSNR makes it difficult to generalize the results to mainstream streaming.
- Unproven Impact: Without comprehensive 4:2:0 testing, full VMAF RD curves, or subjective tests, the claimed 10% savings remains unproven.
- Best Bet? Pre-only HEVC: This has the most potential because it maintains compatibility with existing HEVC decoders, which is a practical advantage. However, the testing was limited to 4:4:4, so the real-world impact is still uncertain.
Recommendations
- Test on 4:2:0: Real-world streaming is in 4:2:0, not 4:4:4. We need to see how the 10% savings holds up there.
- Show VMAF RD Curves: They showed related VMAF results, but not full VMAF RD curves. These are needed to verify perceptual quality and bitrate savings.
- Run Subjective Tests: If the goal is perceptual optimization, let’s see real human feedback. This would provide more comprehensive validation of the perceptual gains.
Overall Score: 6.4/10
The technology is an impressive proof of concept, but the lack of realistic testing and practical use cases limits its real-world value.
Scoring Summary
| Category | Score/10 | Reasoning |
|---|---|---|
| Compression Efficiency | 6 | The 10% savings is only for 4:4:4 at high bitrates, which isn’t used in streaming. No comprehensive VMAF RD curves, so real-world impact is unclear. |
| Encoding Complexity | 6 | Needs high-end GPUs for real-time encoding, but pre-only mode is lighter. |
| Decoding Complexity | 8 | Real-time on consumer GPUs for post-processed modes, but pre-only mode is just standard HEVC. |
| Compatibility | 6 | Technically compatible, but only if using 4:4:4 HEVC, which is rare. No validation for 4:2:0. |
| Intellectual Property | 6 | Unclear licensing and proprietary neural nets. |
| Overall Score | 6.4 | Clever idea with poor execution for real-world testing and use cases. |