Streaming Learning Center Where Streaming Professionals Learn to Excel
Streaming Learning Center Where Streaming Professionals Learn to Excel

Related Articles


A new AI-based codec proved 18% more efficient than VVC but substantial decoding requirements will limit short-term commercial application. Here’s a summary of the white paper.
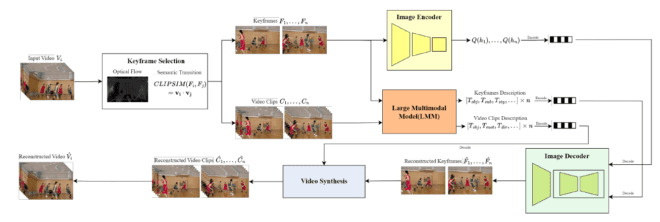
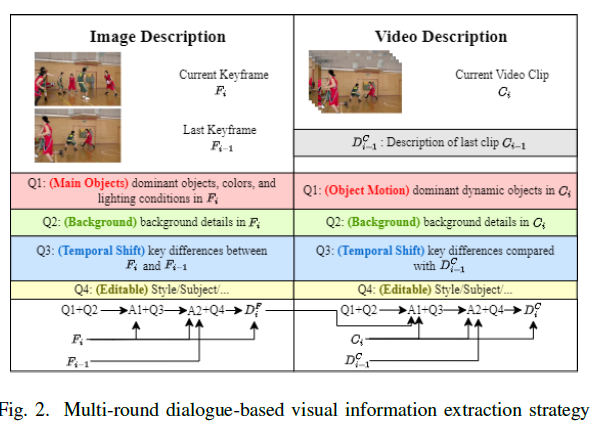
In December 2024, researchers from Fudan University introduced M3-CVC, an AI-based video compression framework that combines large multimodal models (LMMs) for semantic understanding and conditional diffusion models (CDMs) for high-fidelity reconstruction. The framework employs a semantic-motion composite strategy for keyframe selection, which helps retain critical information in the video sequence. This approach proved 18% more efficient than VVC when evaluated across a diverse set of test videos.
M3-CVC’s strength lies in its ability to preserve and prioritize the semantic meaning of video content. The framework uses LMMs to perform spatiotemporal analysis and CDMs to reconstruct video frames, ensuring that meaning and visual quality are maintained even under ultra-low-bitrate conditions. M3-CVC uses a dialogue-based LMM approach to extract hierarchical spatiotemporal details, enabling both inter-frame and intra-frame representations. This not only improves video fidelity but also enhances encoding interpretability.
Contents
Experimental Setup and Results
Here’s the setup. The researchers trained the model on the MSR-VTT dataset, a diverse collection of video content, and focused on optimizing the keyframe codec to maximize fidelity during compression. The training videos were adjusted to 512×320 at 8 fps to reduce complexity. While this configuration prioritizes computational efficiency for the research, it limits the generalizability of the results to higher-resolution, high-frame-rate scenarios like 4K or 60 fps streaming.
The researchers tested the codec on datasets widely used in video codec analysis, including the UVG dataset, the MCL-JCV dataset, and HEVC Class B and Class C datasets. These datasets provided a range of resolutions and content complexities to measure M3-CVC’s performance.
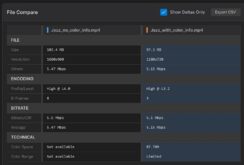
On the encoding side, M3-CVC shows notable promise. Tests revealed that it could encode video sequences in just 76.7 seconds on an NVIDIA RTX 3090 GPU, compared to 1,519.7 seconds for VVC under similar conditions. Compression efficiency was evaluated using bits per pixel (bpp), while video quality was assessed using LPIPS and CLIP-sim.
The results demonstrated that M3-CVC significantly outperforms the state-of-the-art VVC standard in ultra-low bitrate scenarios, particularly in preserving semantic and perceptual fidelity. However, traditional metrics such as PSNR and VMAF were notably absent, signaling the researchers’ emphasis on semantic and perceptual fidelity over pixel-level accuracy.
Decoding Challenges and Limitations
While the 18% efficiency advantage over VVC is alluring, M3-CVC faces significant barriers to practical deployment, particularly on the decoding side. The decoding process relies on GPU acceleration due to the computational intensity of the framework’s diffusion models, which require iterative denoising guided by semantic representations. On an NVIDIA RTX 3090 GPU, about a $900 GPU, M3-CVC needed 142.5 seconds to decode a sequence, compared to just 23.1 seconds for VVC on an Intel Xeon Gold 6230 CPU.
This reliance on high-performance GPUs highlights the decoding challenge presented by M3-CVC. While CPUs and dedicated codec silicon dominate current playback environments and NPUs (Neural Processing Units) are increasingly common in mobile and desktop devices, neither can efficiently decode M3-CVC. Adapting M3-CVC for scalable, consumer-grade hardware would likely require significant advancements in ASICs or next-generation NPUs tailored for generative AI workloads, delaying broad-scale deployment for 6-8 years or longer.
In its current state, M3-CVC’s best fit is in specialized environments where its decoding limitations are less of a concern. These include high-performance computing scenarios, cloud-based video processing, and video analytics. For instance, industries like medical imaging and video surveillance, which demand high semantic fidelity and compression efficiency, could benefit from M3-CVC’s advanced capabilities.
Lessons for AI-Driven Codecs
M3-CVC underscores an important lesson for AI-driven codecs: efficiency alone is not enough for broad applications like general-purpose streaming. Practical decoding workflows must be a priority to achieve widespread adoption. Compatibility with NPUs or similarly scalable architectures is essential for ensuring that codecs like M3-CVC can transition from research innovations to real-world implementations. Without this focus, even the most advanced codecs risk being confined to niche markets or facing long delays in adoption as hardware evolves.
While decoding complexity currently limits M3-CVC’s practical applications, its innovative design and performance metrics represent a milestone in video compression technology. As AI hardware and software continue to advance, frameworks like M3-CVC pave the way for a future where video codecs combine efficiency, intelligence, and practicality, transforming how video is delivered and consumed across industries.