 Streaming Learning Center Where Streaming Professionals Learn to Excel
Streaming Learning Center Where Streaming Professionals Learn to Excel


Related Articles




Demuxed is the annual conference for video engineers by video engineers. Held on October 17 and 18 in San Francisco, the conference included 31 speakers giving talks in rapid-fire fashion ranging in duration from 10 to 30 minutes. To use a well-worn but appropriate metaphor, the experience is like drinking from a fire hose: almost impossible to comprehend and digest in real time. I attended the first day this year and watched several talks from the second day via the video library on Twitch.tv.
Overall, the videos are an invaluable source of information on a wide variety of topics. In this story, I’ll review some of the talks that I found most interesting, which obviously will be unique to me. Before glancing through my list below, I strongly suggest that you review a complete list of speakers and topics. You’ll likely find multiple talks that you’ll want to watch in addition to those that I discuss below, listed in order of presentation.
Contents
Demuxed Day 1
The conference started with a bang thanks to a talk entitled “Streaming the 2018 FIFA World Cup Live in UHD with HDR” by Fubo.TV’s Billy Romero and Thomas Symborski. The object of the exercise was delivering a four-rung HEVC encoding ladder ranging from 2160p at 16 Mbps to 720p at 3.5 Mbps, all with HDR10 HDR metadata (Figure 1). The entire workflow was cloud-based and involved transcoding the 70 Mbps input feed in the cloud on AWS C5.18 X-Large instances.
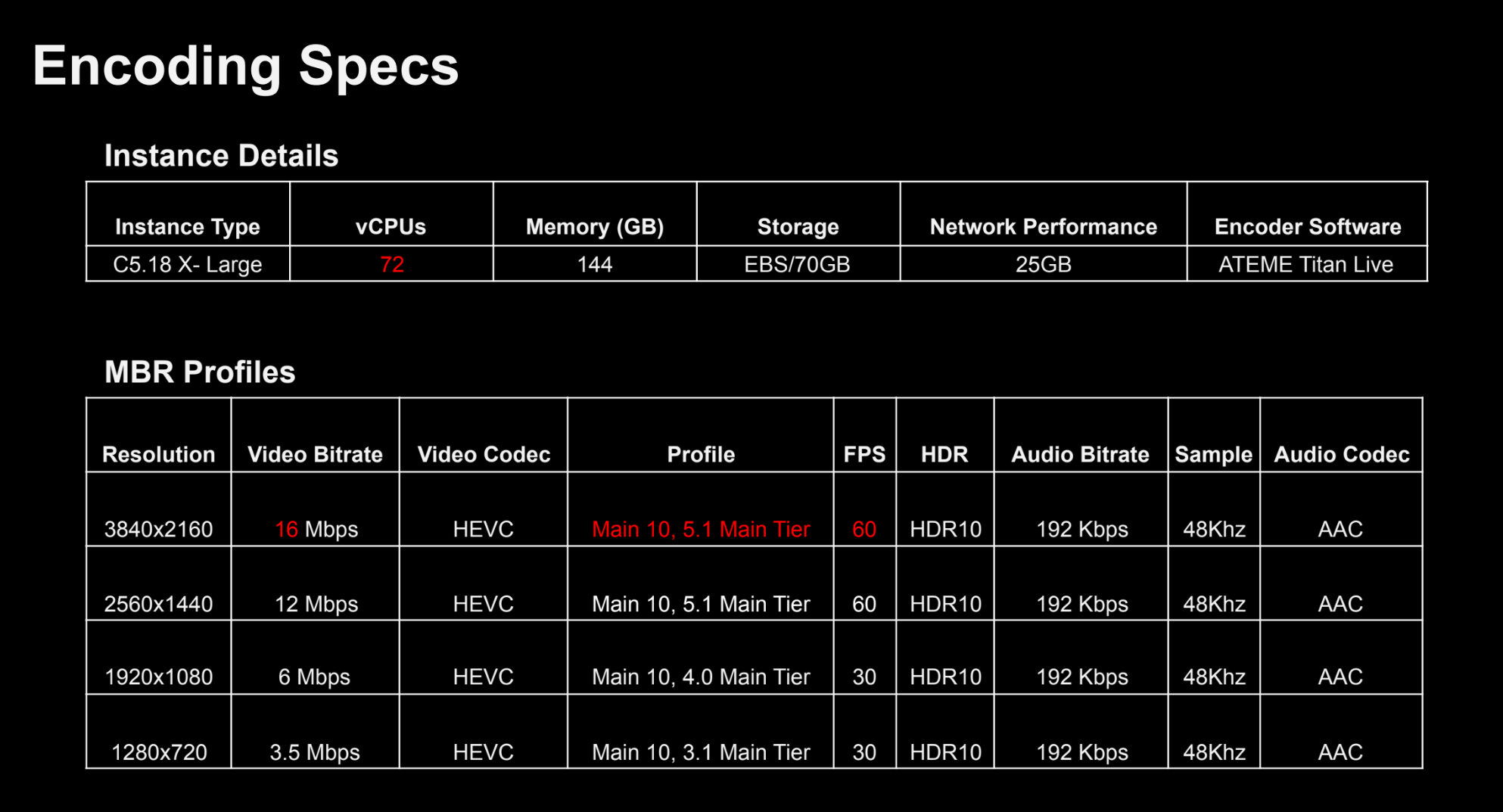 Figure 1. Instance details and the encoding ladder used for the FIFA World Cup 4K delivery with HDR10.
Figure 1. Instance details and the encoding ladder used for the FIFA World Cup 4K delivery with HDR10.
During the talk, the presenters delivered a blueprint for any video engineer seeking to produce a similar experience, covering the network setup for acquisition, encoder selection, packaging and storage, and client and player considerations, including lessons learned delivering to Amazon Fire TV/Android TV, Roku, Chromecast Ultra, and Apple TV devices using ExoPlayer, AVF, Roku, Shaka, and the Bitmovin players. Ultimately, the presenters advised attendees to “fail fast, learn quickly, and focus on the user experience.”
The next talk in my wheelhouse was “What to Do After Per-Title Encoding” by Ben Dodson and Nick Chadwick from Mux. During the fast-paced talk, Dodson and Chadwick reviewed the history of per-title encoding and many of the foundational theories and challenges. Then the pair detailed how Mux built its own per-title encoding facility using machine learning, and how their per-title encoding extended to per-scene encoding, which enabled live per-title encoding. This is a dense and technically challenging presentation that anyone designing a per-title or per-scene encoder will find invaluable.
Perceived video quality is the very heart of what we do, and Twitter’s Sebastiaan Van Leuven’s talk “Subjective Video Quality Assessment for Mobile Devices” tackled this subject head on. During his ten-minute talk, Van Leuven first reviewed two commonly used techniques for measuring video quality, single-stimulus and double-stimulus Mean Opinion Score (MOS). Briefly, single-stimulus shows a single sample and asks for a rating on a five-point scale, while double-stimulus shows the original video and then the encoded sample, and requests a similar rating. While simple to deploy, both testing methodologies score low on precision and consistency, both with different testers rating the same video and the same tester rating the same video on a different day.
To improve consistency and reliability, Twitter developed an Adaptive Paired Comparison (APC) that shows two samples and asks the subject which is better, like the optometrist asking, “Which looks better, left or right?” This test methodology produces more accurate and reproducible results but can also be very time-consuming. What’s novel about Twitter’s approach is the active learning procedure using a particle filtering simulation that streamlines the sample selection. The short presentation provides an overview, which Van Leuven supplemented with a link to a blog post.
Accelerating AV1 Playback with dav1d
The Alliance for Open Media’s (AOM) AV1 codec launched in mid-2018 but hardware-accelerated playback isn’t expected until mid-2020. This makes software decoder efficiency absolutely critical for deployments over the next 24 month. Many initial tests of AV1 decoding using the AOM decoder libaom, including my own, showed it to be slow and inefficient. For this reason, AOM sponsored the development of a new open-source AV1 decoder called dav1d by the VideoLAN, VLC, and FFmpeg communities.
In their talk entitled Introducing dav1d, “A New AV1 Decoder,” VideoLAN’s Jean-Baptiste Kempf and Two Oriole’s Ronald Bultje described the goals of the project, which include smaller source code, smaller binary executable, and a smaller runtime memory footprint than libaom. During the talk, Bultje reviewed dav1d’s performance to date and predicted that when fully implemented, it will produce similar decode performance to H.264, HEVC, and VP9. While this won’t match the decode efficiency of codecs supported in hardware, it will certainly extend AV1’s usage far beyond where libaom could take it. According to this blog post, dav1d currently works on x86, x64, ARMv7, ARMv8 hardware and runs on Windows, Linux, macOS, Android, and iOS.
As RealEye Media’s David Hassoun pointed out in his presentation, “Multi-CDN Jump Start, Don’t Put All Your Bits in One Basket,” using a single CDN to deliver your traffic means a single point of failure, an unacceptable risk whenever streaming delivery is mission critical. As Hassoun also mentions, a single CDN may also not provide the best experience for many users, and may not be cost effective.
These points made, Hassoun then identified common problems of using multiple CDNs, such as synchronized origins for live streaming, traffic routing, receiving actionable real-time-ish data for QoS and QoE, and cross CDN access security. Then, he suggests multiple solutions to these problems and how to build multiple CDN support all the way down to manifest file creation. Covering a lot of ground in the allotted ten minutes, this presentation is a must see for anyone considering dipping their toes into multiple CDN delivery (Figure 2).
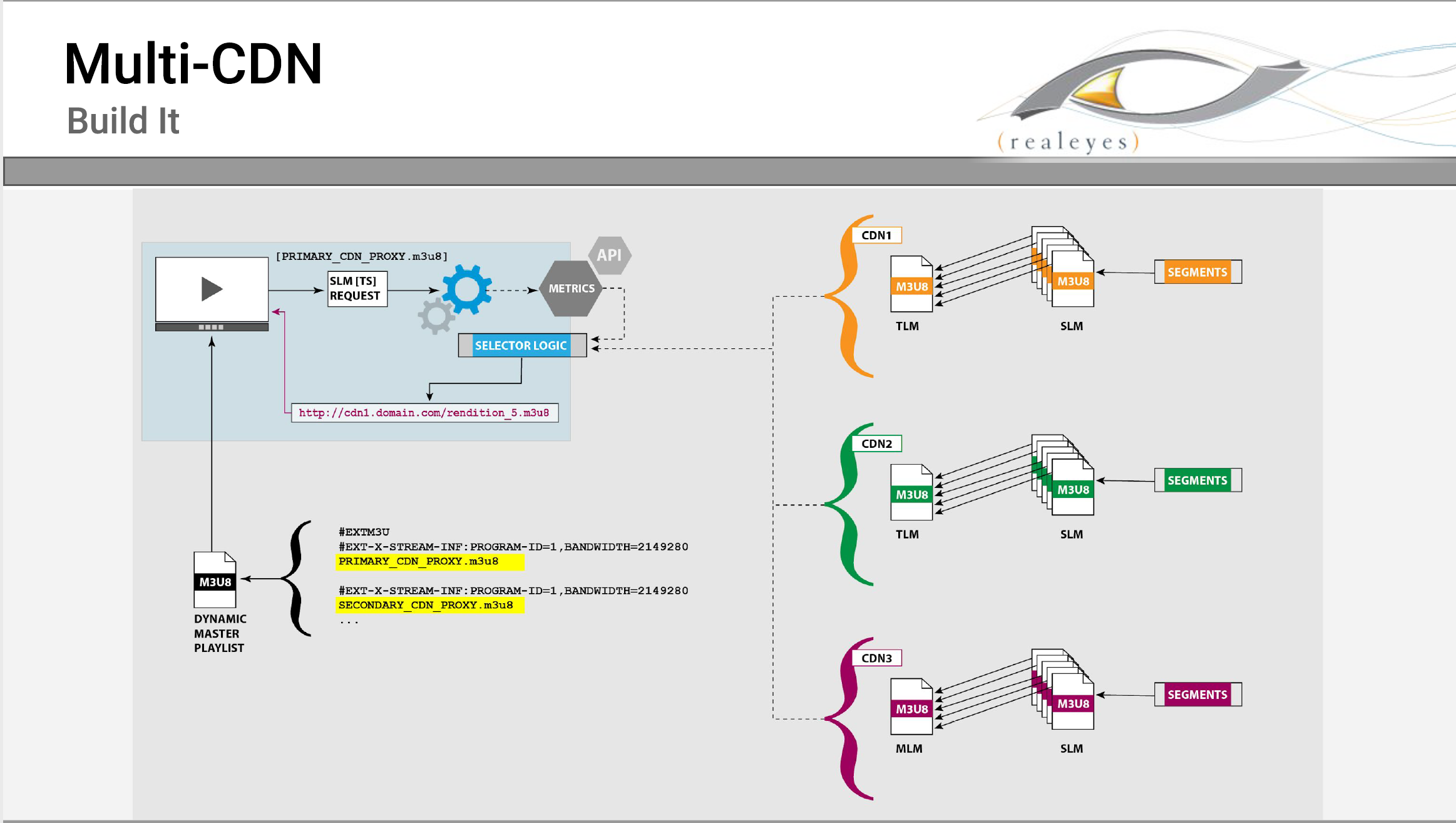 Figure 2. Adding multiple CDN support to a dynamic master playlist.
Figure 2. Adding multiple CDN support to a dynamic master playlist.
Reducing Glass-to-Glass Latency
Glass-to-glass latency is a consistent concern of many live-event producers. While there are several proprietary approaches to reducing live latency, like Wowza Streaming Cloud’s ultra-low latency service, this may not work at the scale required for large events.
One solution that’s gaining traction is Chunked CMAF as comprehensively described by Akamai’s Will Law in his presentation entitled “Chunky Monkey, Using Chunked-Encoded Chunked-Transferred CMAF to Bring Low Latency Live to Very Large Scale Audiences.” Figure 3 illustrates this approach. On top is the traditional way to deliver a segment, which is waiting until it’s completely finalized and stored off. The bottom shows the same media samples packaged in chunks that can be delivered before the complete segment is encoded and saved, which dramatically reduces latency.
 Figure 3. On top is a single segment delivered after completion. On the bottom are the same samples packaged in chunks delivered chunk by chunk.
Figure 3. On top is a single segment delivered after completion. On the bottom are the same samples packaged in chunks delivered chunk by chunk.
Though this approach cuts latency and streamlines network throughput, it also causes multiple issues, like how to estimate bandwidth and how to resolve timing differences between HLS and DASH. Law discussed different solutions to these issues and concluded with a look at standardization efforts for chunked CMAF, as well as commercial vendors and open source tools for implementing this approach.
The last presentation that I caught was “Fabio Sonnati’s ‘Time Machine,’ How to Reconstruct Perceptually, During Playback, Part of the Detail Lost in Encoding.” By way of background, Sonnati is a pioneer of digital video encoding whose articles on per-title encoding and FFmpeg have provided a critical foundation for many practitioners, including myself. This was the first time I met Fabio in person and saw him speak.
In his talk, Sonnati explored whether it’s possible to reconstruct a portion of the quality lost during compression during playback. He started by identifying the classic encoding artifacts produced during encoding, which includes loss of fine detail and film grain, banding, and decrease of contrast and flatness. Given that we know these occur, Sonnati detailed how we might fix these during decompression (Figure 4), and showed several experiments that achieved meaningful increases in VMAF quality by deploying these techniques.

Figure 4. Fixing encoding related problems during decompression and display.
Operationally, Sonnati claimed that these enhancements could be performed in modern browsers using WebGL, including on mobile devices where they could provide the most profound benefit. However, performance tuning and logic considerations must be addressed before widespread deployment.
Demuxed Day 2
As mentioned, I only attended the first day of the conference, so all day two observations are from the archived videos, where I primarily focused on encoding-related presentations. The first talk I watched was Mux founder Jon Dahl’s presentation entitled “Video, Evolution, and Gravity: How Science Affects Digital Video.” As the title suggests, Dahl explored how human physiology and physics have contributed to many of the fundamentals of video encoding and production, including aspect ratio, frame rates, and color management.
Among the many issues tackled, Dahl quantified why many videographers (including this author) detest vertically-oriented video with “Jon’s Law,” which postulates that “the appropriateness of a vertical orientation decreases exponentially with the amount of change.” This explains why still image portraits captured in portrait-mode look so great, while vertically-oriented snippets of sporting events look so awful. At the end, Dahl suggested that all video producers could benefit from learning the science behind human perception to best guide their creative and developmental efforts.
Next up was John Bartos’s talk on low latency HLS, which was a great complement to Will Law’s talk on chunked CMAF. Besides being a senior software engineer at JW Player, Bartos is one of the core maintainers of open-source player HLS.js, a JavaScript HLS client that uses the Media Source Extension in a browser to play HLS and other ABR formats. Bartos described how he hopes to reduce HLS playback latency from 30 seconds to about 2 seconds without “upending” your video stack with technologies like WebRTC or RTMP.
Briefly, low latency HLS works by advertising low-latency segments in the manifest files and then transferring them via chunked transfer encoding as described above in Law’s presentation. Servers then push segment chunks from the transcoder to the clients for playback. While this sounds simple enough, the required transcoder/server/client integration makes this a technology better implemented via a standard, and Bartos concludes by listing some of the companies involved in the efforts to create a low-latency HLS standard.
The next session I watched was by Comcast’s Alex Gilardi, entitled “The Virtues of Recycling in Multi-Rate Encoding.” The high-level problem is that when producing an encoding ladder, most encoders perform some level of analysis for each layer, which is wasteful given that the source video is identical for all the layers.
By recycling, Galardi was referring to analysis information gathered during low-resolution encodes that could be used in higher-resolution encodes, which the flow suggested in Figure 5. Complicating this recycling is the fact that the lower resolution information has to be refined in some instances to apply to the higher resolution files. In his talk, Galardi discussed three different refinement alternatives, the fastest of which yielded a speed boost of 2.43x without a quality penalty when encoding high-resolution files using the HEVC codec. Note that while this approach decreases overall CPU cycles spent on the encoding, it will increase end-to-end latency as compared to a parallel encoder, since the lower-resolution files needed to be encoded before the higher-resolution files. This schema makes this approach impractical for live encoding.
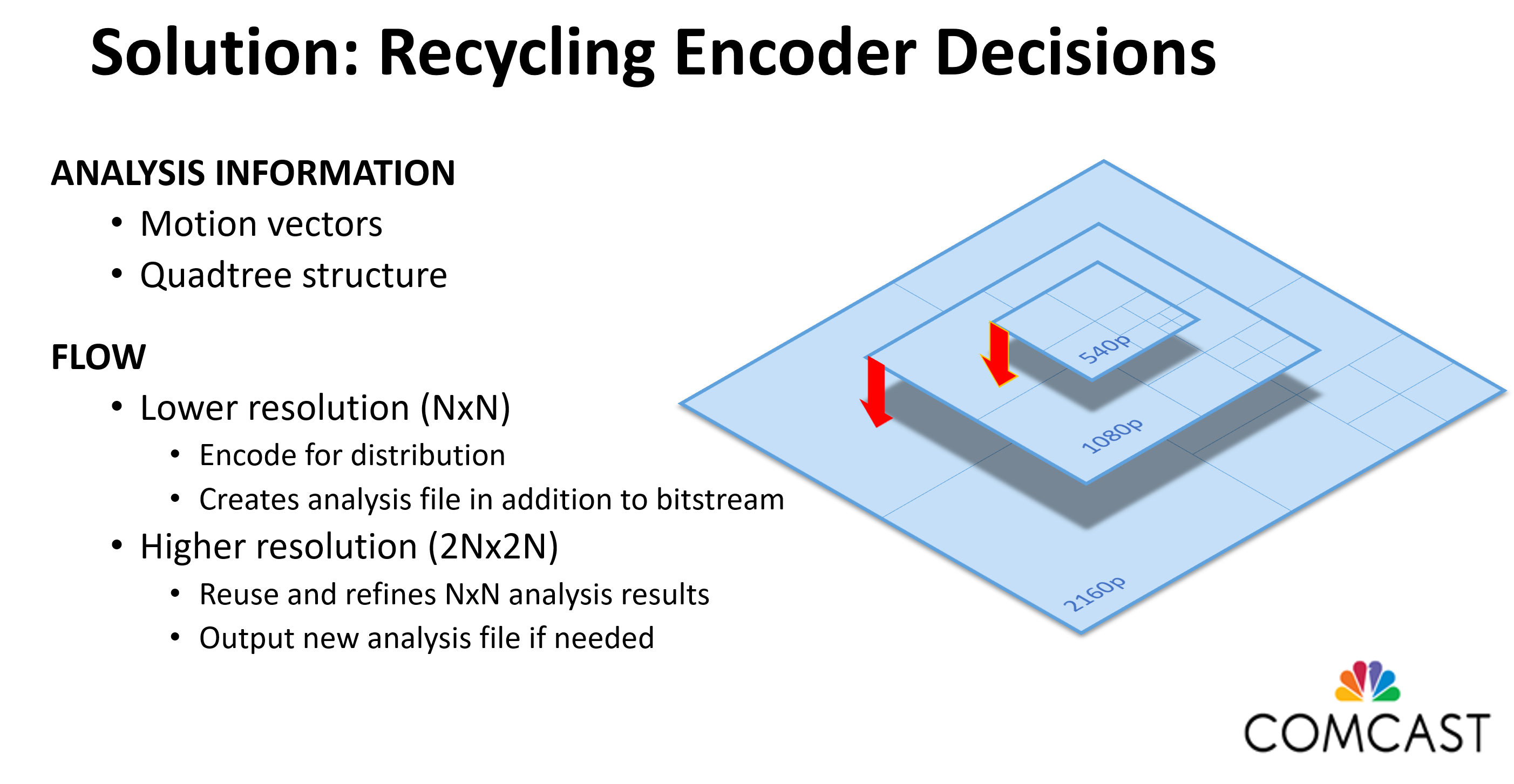 Figure 5. Reusing analysis information to accelerate the production of an encoding ladder.
Figure 5. Reusing analysis information to accelerate the production of an encoding ladder.
While Comcast proved this approach using HEVC, it should also work for other codecs like AV1 and VP9. On his last slide, Galardi included the FFmpeg script necessary to implement this approach, which will definitely simplify experimentation.
Deploying Subjective Video Quality Evaluations
The next presentation that caught my eye was from Intel’s Vasavee Vijayaraghavan, whose talk was entitled “Towards Measuring Perceptual Video Quality and Why.” Vijayaraghavan started by describing objective metrics like SSIM and PSNR, which are automatable and therefore easy to use. However, she stated that these metrics often don’t accurately correlate with the human visual system, which limits their utility.
Conversely, subjective evaluations that produce a Mean Opinion Score (MOS) are time-consuming and expensive to produce but are the best predictor of human ratings. In 4K encoding tests performed at Intel, Vijayaraghavan found that scores above a MOS rating of 4.5 were imperceptible to viewers and recommended setting your bitrate to produce a maximum MOS rating of 4.5, or around 13 Mbps (Figure 6). As shown below, this still produced a very significant bandwidth savings over higher data rate encodes.
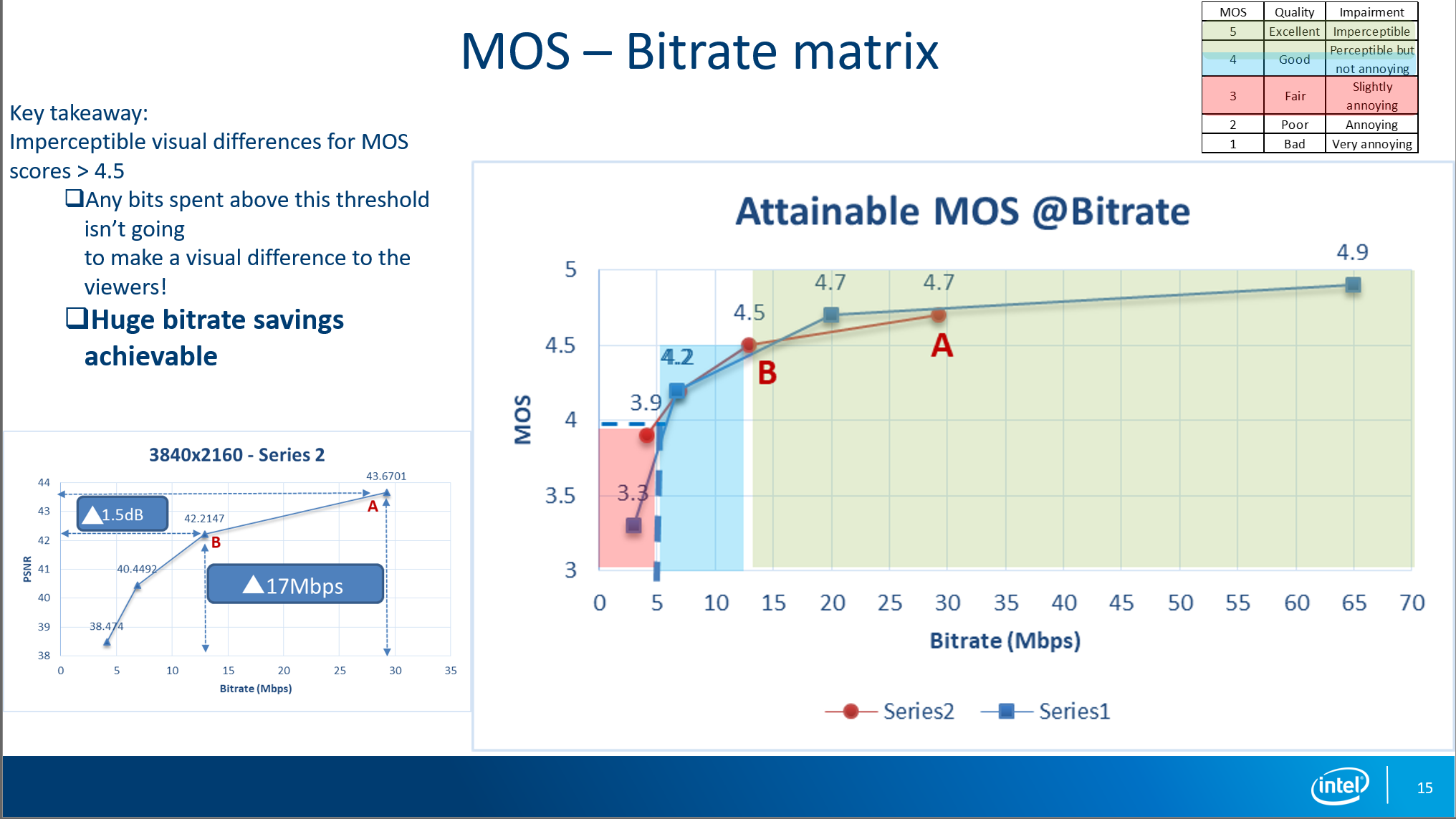 Figure 6. Intel found that MOS ratings above 4.5 produced no perceptible improvement.
Figure 6. Intel found that MOS ratings above 4.5 produced no perceptible improvement.
In a production environment, Vijayaraghavan recommended implementing a per-category encoding scheme by choosing representative videos from the most commonly used content types, encoding at different video quality points, and measuring the MOS scores as above. Once you decide the appropriate maximum rate, you can create an appropriate encoding ladder and apply that to all videos in that category. She did warn, however, that this analysis must be performed separately for each content category and encoder/codec.
The final talk I watched was by Stephen Robertson from YouTube, who was supposed to talk about Machine learning for ABR in production. Apparently, however, machine learning at YouTube is not in production, so Robertson gave a peripatetic talk covering multiple topics, including the challenges of implementing machine learning at YouTube and some pretty interesting studies of video quality.
On a more practical level, he began his talk by sharing that YouTube was distributing about 1 GB of AV1 encoded video per second in mid-October, which he expected to increase to over 1 TB/second by the end of October. He did share that AV1 was not the most cost-effective approach, but that YouTube was deploying AV1 to show that they are “deadly serious” about the codec and “dedicated to its success.”
Overall, the diverse range of topics and speakers make Demuxed a valuable resource for all video producers. Again, I recommend that you scan the list of talks to see if there are any that apply to your practice.



