Streaming Learning Center Where Streaming Professionals Learn to Excel
Streaming Learning Center Where Streaming Professionals Learn to Excel

Related Articles




Let’s start by defining some terms and concepts. Artificial intelligence refers to a program that can sense, reason, act, and adapt. One AI subset that’s a bit easier to grasp is called machine learning, which refers to algorithms whose performance improves as they are exposed to more data over time.
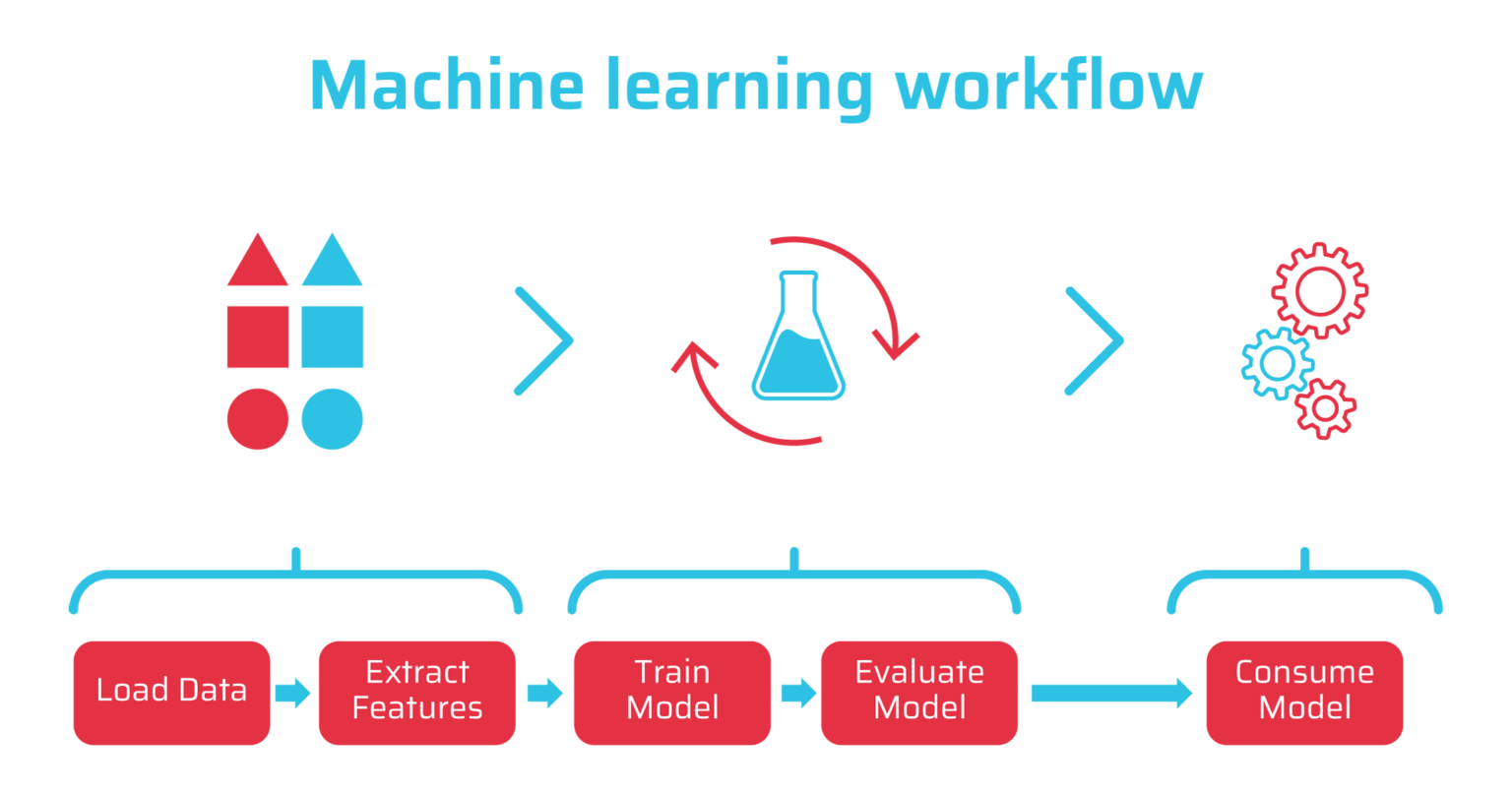
Machine learning involves the five steps shown in the figure below. Let’s assume we’re building an application that can identify dogs in a video stream. The first step is to prepare your data. You might start with 100 pictures of dogs and then extract features, or represent them mathematically, that identify them as dogs: four legs, whiskers, two ears, two eyes, and a tail. So far, so good.
Then it’s time to run the model. Here, you export the model for deployment on an AI-capable hardware platform like the NETINT Quadra. What makes Quadra ideal for video-related AI applications is the power of the Neural Processing Units (NPU) and the proximity of the video to the NPUs. That is, since the video is entirely processed in Quadra, there are no transfers to a CPU or GPU, which minimizes latency and enables faster performance. More on this is below.
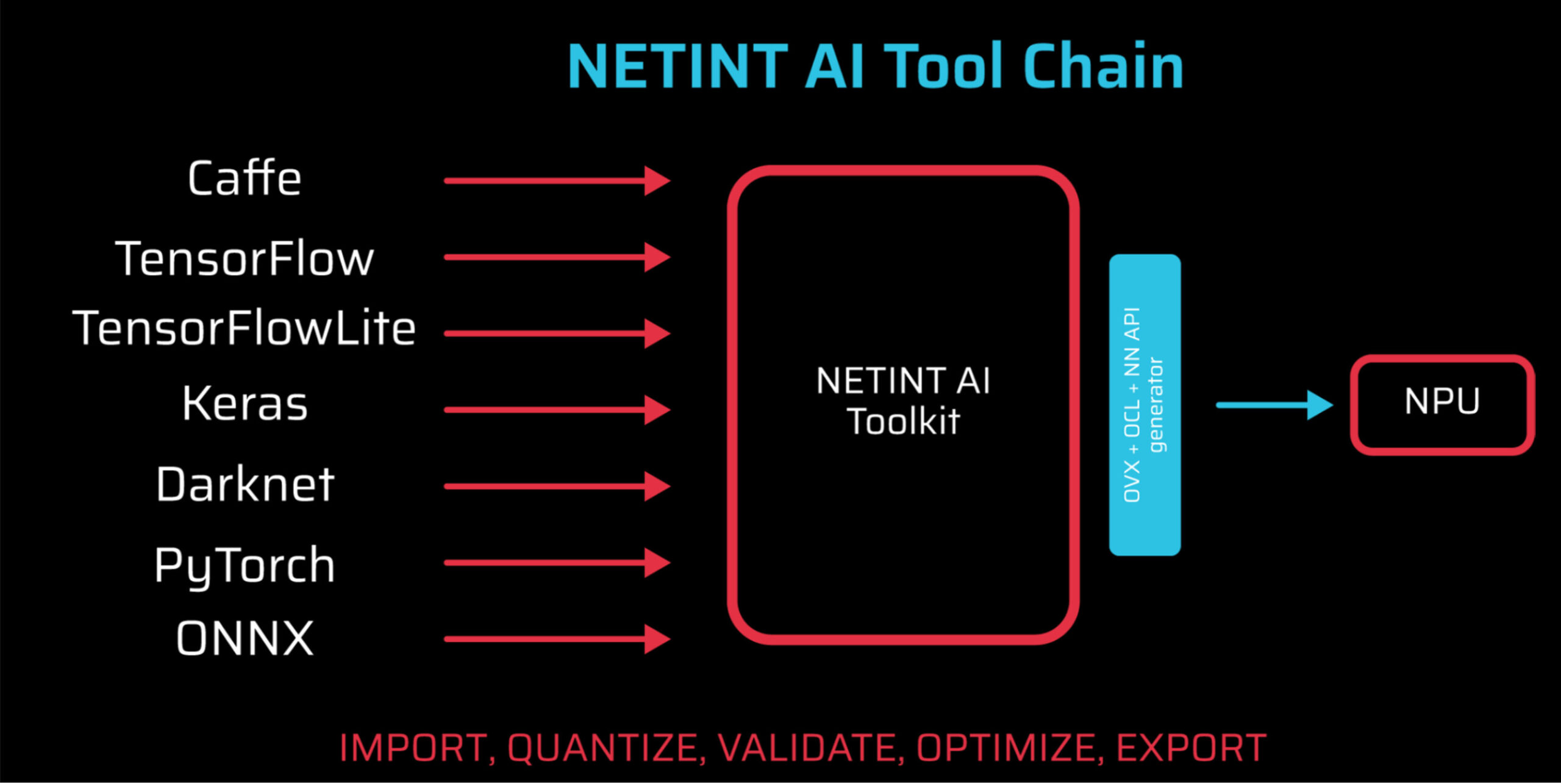
Figure 2 shows the NETINT AI Toolchain workflow for creating and running models on Quadra. On the left are third-party tools for creating and training AI-related models. Once these models are complete, you use the free NETINT AI Toolkit to input the models and translate, export, and run them on the Quadra NPUs – you’ll see an example of how that’s done in a moment. On the NPUs, they perform the functions for which they were created and trained, like identifying dogs in a video stream.
Most users will access the ROI function via FFmpeg, where it’s presented as a video filter with the filter-specific command string shown below. To execute the function, you call the filter (ni_quadra_roi), enter the name and location of the model (yolov4_head.nb), and a QP value to adjust the quality within each box (qpoffset=-0.6). Negative values increase video quality, while positive values decrease it so that the command string would increase the quality of the faces by approximately 60% over other regions in the video.
-vf ‘ni_quadra_roi=nb=./yolov4_head.nb:qpoffset=-0.6’
Obviously, this video is highly compressed; in a surveillance video, the ROI filter could preserve facial quality for face detection; in a gambling or similar video compressed at a higher bitrate, it could ensure that the players’ or performers’ faces look their best.

In terms of performance, a single Quadra unit can process about 200 frames per second or at least six 30fps streams. This would allow a single Quadra to detect faces and transcode streams from six security cameras or six player inputs in an interactive gambling application, along with other transcoding tasks performed without region of interest detection.
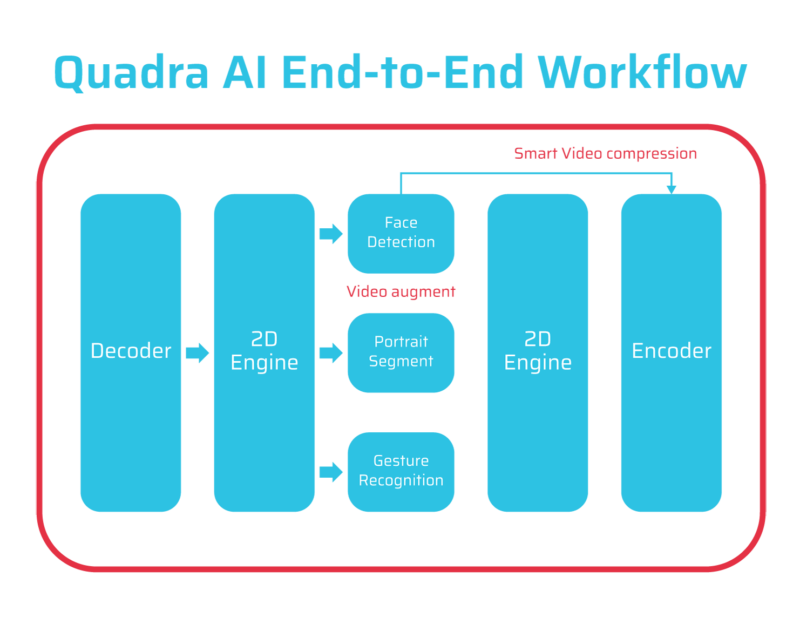
Figure 4 shows the processing workflow within the Quadra VPU. Here we see the face detection operating within Quadra’s NPUs, with the location and processing instructions passing directly from the NPU to the encoder. As mentioned, since all instructions are processed on Quadra, there are no memory transfers outside the unit, reducing latency to a minimum and improving overall throughput and performance. This architecture represents the ideal execution environment for any video-related AI application.