 Streaming Learning Center Where Streaming Professionals Learn to Excel
Streaming Learning Center Where Streaming Professionals Learn to Excel

Related Articles




Maya Angelou once said that “You can’t really know where you are going until you know where you have been,” and so it is with per-title encoding. What began as a one-dimensional data rate adjustment that reflected the simple reality that all videos encode differently is now a complex analysis that incorporates frame rate, resolution, color gamut, and dynamic ranges, as well as delivery network and device-related data. Along the way, video quality metrics have advanced as well, as needed to supply the quality-related data that feeds the per-title algorithms. In this article, I’ll review the history of per-title encoding technologies to provide the perspective to understand what features to look for when choosing a technology and/or service provider.
Contents
It all Started with Optimization
Though Netflix is generally credited with inventing per-title encoding with their seminal December 2015 article Per-Title Encode Optimization, several technologies existed before then that customized file data rate according to the complexity of the source file. These include technologies like Beamr’s Content Adaptive BitRate (CABR) and Constant Rate Factor (CRF) technologies included in codecs like x264, x265, and VP9.
Beamr’s CABR is an iterative frame-by-frame encode that keeps encoding at increasingly aggressive encoding parameters so long as frame quality is “perceptibly identical” to original file quality
as measured by Beamr’s video quality metric. Once the quality goes below this, the encoder reverts back to the previous encode and moves on to the next frame.
CRF is more of a black box. To explain the operation, with most streaming encodes you specify a bitrate target, say, bitrate=5 Mbps, and the encoder outputs a 5 Mbps file. If the content is a talking head, the quality will be good; if a soccer match, it could get dodgy. In data rate mode, the encoder varies quality to meet the data rate.
With CRF, you specify a CRF level from 0-51, say CRF=25, and the encoder outputs a file with CRF 25 quality level. If the content is a talking head, the data rate might be 2 Mbps; if a soccer match it could be 15 Mbps. In CRF mode, the encoder varies data rate to deliver the requested quality. CRF performs well as a per-title technology when deployed with a data rate cap (encode at quality CRF=25 but don’t exceed 5 Mbps). This mode is called capped CRF and it’s used by vendors like Vimeo and JWPlayer as well as several large VOD producers.
In general, optimization technologies are the only practical way to adjust file data rate during live events. For this reason, live per-title encoding technologies like AWS Elemental QVBR and Harmonic’s EyeQ, are both optimization technologies. In addition, though Brightcove uses a much more advanced per-title technology for VOD, it uses capped CRF for live videos.
All optimization technologies have one very serious limitation; they can’t change any aspect of the file or encoding ladder other than bitrate. For perspective, note that whenever you evaluate a per-title encoding technology you typically compare it to a fixed encoding ladder. You see this in Figure 1, with the fixed ladder on the left and two per-title technologies on the right. Per-title B is an optimization technology; you feed it the number of rungs and resolutions in the original encoding ladder and it adjusts the data rate–and only the data rate–of those rungs.
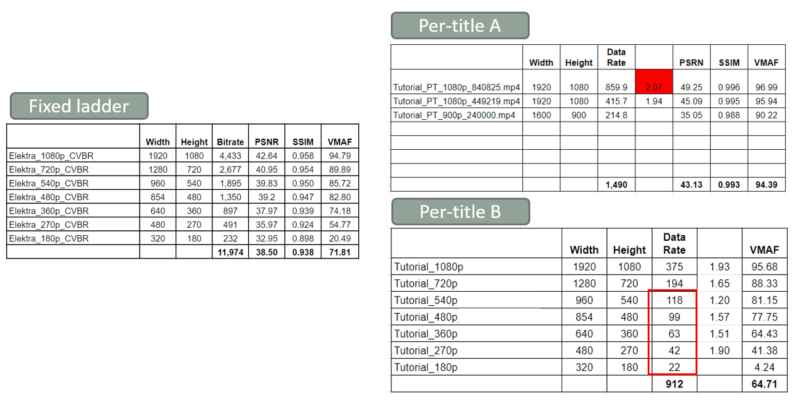
In contrast, you feed technology A the original file and it decides how many rungs the encoding ladder needs and their data rate and resolution. In the figure, you see that technology A not only reduces the number of rungs (and encoding costs), it increases the resolutions of those rungs and the associated VMAF quality. Because optimization technologies can only adjust the data rate, and not the number of rungs or their resolution, they typically don’t perform as well as other per-title technologies that can adjust all three variables.
Still, optimization technologies were all that existed until Netflix made its ground-breaking announcement.
Netflix Debuts Per-Title Encoding
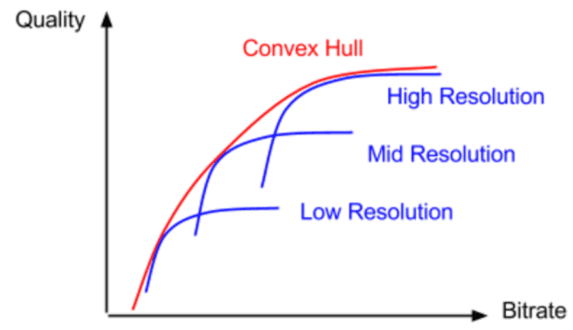
Netflix debuted its per-title technology in December 2015. At a high level, Netflix uses a brute-force encoding technique that encodes each source file to hundreds of combinations of resolution and data rate to find the “convex hull,” which is the shape that most efficiently bounds all data points. You see this in Figure 2.
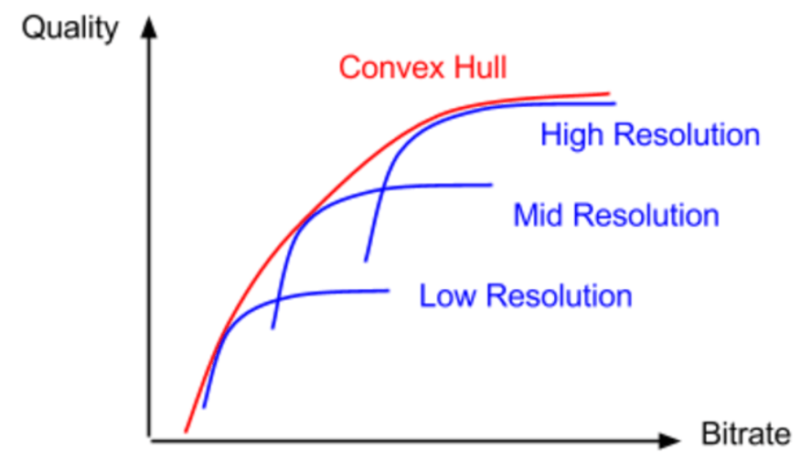
Interestingly, the metric that originally drove Netflix’s decision engine was PSNR, which is a still image metric that doesn’t incorporate the concept of motion. Netflix replaced PSNR with VMAF in June 2017. Briefly, VMAF stands for Video Multimethod Assessment Fusion (VMAF) which fuses four quality metrics, including a simple motion metric. When launched, Netflix posted data showing that VMAF had a higher correlation with subjective evaluations than PSNR, which is consistent with my use of VMAF.
Others Join the Party
By early 2016, it was clear that many other organizations had been working on per-title implementation for quite some time. At the 2016 International Symposium on Electronic Imaging, YouTube presented a paper that detailed their approach. For perspective, note that YouTube and Netflix approach the problem from two very different perspectives. Netflix encodes comparatively few videos but most are watched by millions of paying customers which justifies its expensive encoding schema that delivers the absolute best quality at the lowest possible bitrate.
In contrast, in early 2016, YouTube was receiving 300 hours of video every minute, with some watched by millions of viewers but most watched by much lower numbers. This called for a much faster and less expensive per-title implementation. Interestingly, YouTube’s technique combined artificial intelligence with file complexity data supplied by a single 240p CRF encode of the source file.
Also in 2016, Capella Systems launched a feature called “source adaptive bitrate ladder,” or SABL in their flagship VOD encoder, Cambria FTC. SABL uses CRF to measure file complexity with scripting available to adjust both the number of rungs in the ladder and their resolution depending upon the CRF results. Many other commercial implementations appeared, including per-title features from online video platform Brightcove and cloud encoding vendor Bitmovin.
Per-Scene Adaptation
In 2018 Netflix debuted scene-based Dynamic Optimization. As shown in Figure 3, rather than dividing the video up into arbitrary two-second or three-second GOPs or segments, Dynamic Optimization divides the video into scenes and encodes each scene separately. While this creates dynamic GOP and segment lengths, ABR stream switching continues to work effectively because all ladder rungs share the same GOP and segment lengths.
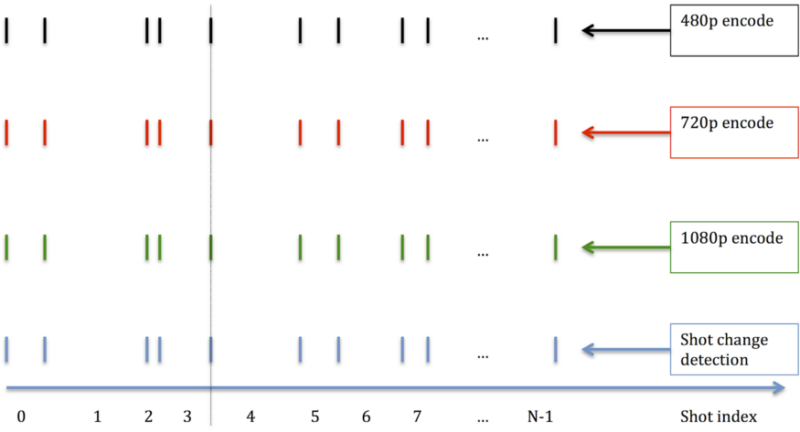
Intuitively, scene-based encoding makes a lot of sense. Customizing encoding parameters for an individual scene should be more efficient than trying to find the optimal encoding configuration for a segment containing two or more scenes that could be comprised of wildly different content. In addition, changing encoding parameters at a scene change would obviously be less noticeable than changing parameters within a scene. Ultimately, Netflix’s computed efficiency numbers speak for themselves; as measured by VMAF, Dynamic Optimization enabled Netflix to reduce the bitrate of x264, VP9 (libvpx), and x265 by 28.04%, 37.61%, and 33.51% respectively while retaining the same quality.
Though shot-based per-title is alluring, it creates significant issues on the player side, particularly for applications that involve advertising insertion. At the very least, you’ll need custom players/apps on virtually all platforms, and even then, it may be very complicated to insert advertising at the desired timings. So, definitely check out the player side before you start tinkering with the encoding side.
The next advancement came from a completely different direction and affirmatively answers the question, “would you create your encoding ladder differently if you knew which devices were playing your content and at which connection speeds?”
Incorporating Device and Network Data
Per-title encoding techniques that incorporated playback data appeared from three companies at roughly the same time, Brightcove, Mux, and Epic Labs, now owned by Haivision. The best description is provided in a white paper entitled, Optimizing Mass-Scale Multi-Screen Video Delivery, authored by streaming media legend Yuriy Reznik and five colleagues from Brightcove.
The paper describes Brightcove’s Context-Aware Encoding technology which analyzes both content and “the estimates of stream load probabilities at each rate…for each client.” It continues, “In computing final optimization cost expression, CAE generator aggregates estimates obtained for each type of client according to usage distribution, also provided by the analytics module. In other words, CAE profile generation is really an end-to-end optimization process for multi-device /multi-screen delivery.”
The paper analyzes the three usage patterns shown on the left in Figure 4 and presents the unique encoding ladder created for each usage pattern from the same content. The first usage pattern is mobile-centric, the second more general-purpose, and the third IP-TV-centric, with 100% of all delivery to TVs with an average bandwidth of about 36 Mbps. While the difference between the first two encoding ladders is subtle, the third ladder stands out as having the fewest rungs, the lowest overall total bitrate, and the highest-quality top rung. This reduces encoding and storage costs and improves QoE, albeit only slightly.
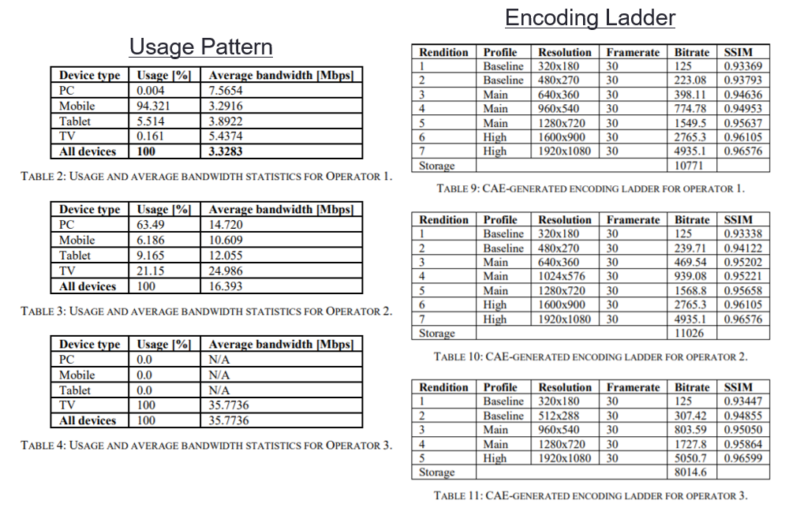
Factoring playback data into the ladder creation analysis makes sense, but where to get the data and in what form? For Brightcove, which deploys an end-to-end platform for most customers, this is obviously easy since it has all the data. Ditto for Mux since its flagship product is Mux Data, a Quality of Experience monitoring tool. For Epic, which runs what appears to be a standalone encoder, and other encoding products and services, the answer is less clear. We contacted Haivision about this and other details but they weren’t ready to discuss how they will implement their recently acquired product.
So while the concept is alluring, how you would actually implement it outside of a service like Brightcove or Mux is unclear. It’s not rocket science; Brightcove detailed the summary data incorporated into their analysis into a single table, and Reznik details the algorithm used to apply the data in this paper. But like the quality metrics that direct the content-related aspects of encoding, algorithms that apply this data will likely vary from implementation to implementation. It’s also very likely that most existing encoding products and services that aren’t plugged into an end-to-end solution are likely not even considering this type of integration.
Another variable addressed in the Brightcove paper is multiple-codec implementations. Here, the paper states, “One of the features of CAE profile generator is the capability to generate ABR profiles for a plurality of existing codecs. In this case, the generator also uses information about support of such codecs by different categories of receiving devices. Such information is supplied as part of operator usage and bandwidth statistics, provided by the analytics engine. The use of multi-codec profile generation leads to additional savings in the total number of renditions and quality gains achievable by clients that can switch between the codecs.”
Incorporating multiple codecs into a single ladder also makes a lot of sense. Though Apple recommends completely separate encoding ladders for H.264 and HEVC content, testing I performed in 2018 shows that a hybrid ladder with H.264 in the lower rungs and H.265 in the upper, works just fine (see here, page 84). Reznick and his Brightcove coworkers explored the same issue here. Producing a single hybrid ladder saves both encoding and storage costs making it the best option for most producers delivering both codecs, making the ability to create hybrid codec encoding ladders a valuable feature for per-title technologies.
Frame Rate and Dynamic Range
Many premium content services distribute HDR video shot at 60 frames per second (fps) or faster. Though dynamic range considerations are comparatively new, producers have reduced the frame rates of the very lowest rungs of their encoding ladders for quite some time. However, none of the per-title technologies discussed to this point have highlighted the ability to automatically adjust the frame rate of ladder rungs. This issue is exacerbated by 50/60 fps videos and faster where two or three frame rate switches might be necessary to represent a smooth progression of quality from higher to lower bitrates.
Another similar problem relates to dynamic range. While high dynamic range (HDR) is clearly preferable in the top rungs of the encoding ladder, it may be incompatible or otherwise undeliverable to lower rungs. Clearly, per-title techniques addressing premium content with high frame rates and HDR must also address how to scale frame rate and dynamic range, along with all other previously discussed parameters, in a single encoding ladder.
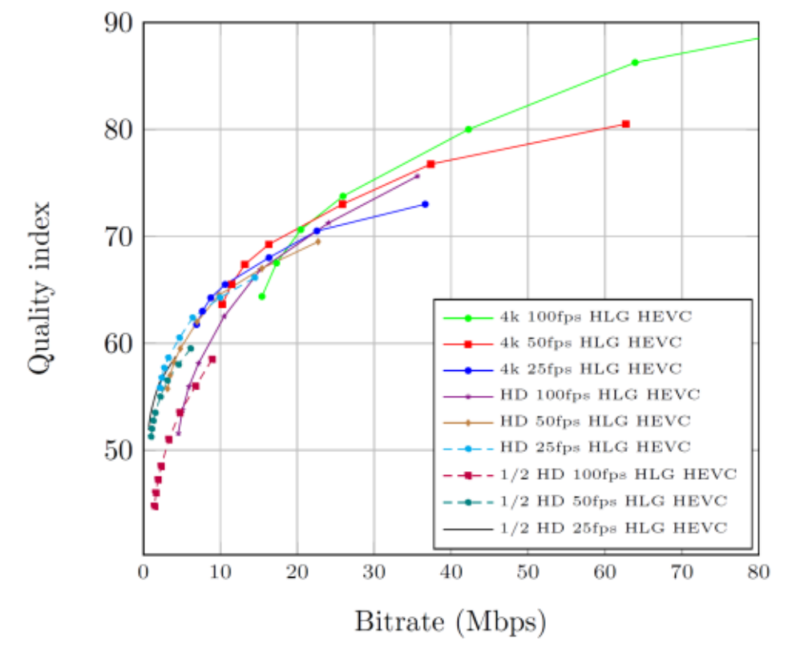
Streaming vendor ATEME tackles frame rate and dynamic range adaptation (and more) in their paper Forward-looking content-aware encoding for next-generation UHD HDR WCG HFR. The paper explores the impact of frame rate adaptation first, using the ATEME Quality Index (AQI) to plot the curves shown in Figure 5, which tracks the quality of streams ranging in resolution from 960×540 to 4K, frame rates ranging from 25 to 100 fps, and data rates ranging from around 1 Mbps to 80 Mbps.
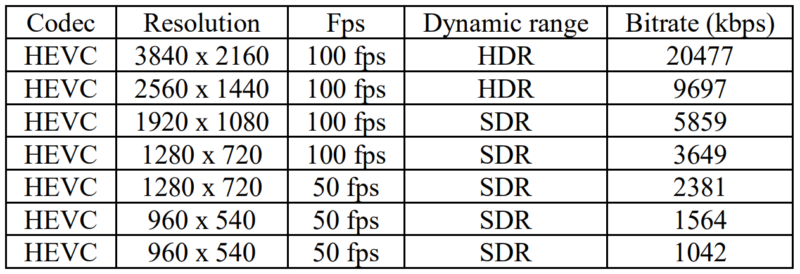
In the paper, the ATEME researchers detail that the ATEME metrics incorporates resolution, frame rate, dynamic range, and color gamut, is codec independent, and uses trellis optimization to produce the optimal rungs for the encoding ladder. Working with 4K 100 fps HDR HLG input from the Tour de France, the system produced the following encoding ladder which delineates switch points for both data rate and dynamic range.
The ATEME authors make it clear that the system can also address other key configuration factors, stating that in addition to “rate, resolution, framerate and dynamic range adaptation, the proposed framework could even handle codec switching if necessary. It would be also possible to derive a single set of profiles addressing several possible screen sizes.”
As a caveat, note that there is some sentiment against changing the frame rate and/or dynamic range within a presentation since this may not preserve the original artistic intent. For example, the Consumer Technology Association Web Application Video Ecosystem – Content Specification CTA-5001-A states “A consistent video frame rate throughout a WAVE Program is recommended to avoid motion artifacts due to frame drops or frame repeats.” Regarding video color characteristics, the document states, “consistent video rendering that utilizes a display’s color gamut and dynamic range is desirable for all Presentations in a Program to create a consistent viewing experience.”
Certainly, the frame rate guidelines are honored more in the breach than in the observance, as Apple’s HLS guidelines have consistently directed producers to configure different frame rates in different ladder rungs. And it’s hard to imagine that any artistic intent would dictate sending HDR streams to an SDR device. Still, these are considerations to keep in mind when configuring your encoding ladders for high frame rate or HDR content.
You’re Only as Good as Your Quality Metric
At this point, another quote comes to mind, in this case, Peter Drucker’s “you can’t manage what you can’t measure.” As applied to this analysis, this means that if your video quality metric doesn’t measure it, you can’t use that metric to manage that parameter.
For example, respecting frame rate, suppose you were comparing two 3 Mbps files encoded from a 60 fps source, one encoded at 1080p and 30fps, the other at 720p and 60 fps. To produce a VMAF (or PSNR or SSIM) score for the 1080p file, you could have to convert the 60 fps source to 30 fps. While this would measure frame quality and even some motion quality (with VMAF) it wouldn’t measure the smoothness advantage 60 fps delivers over 30 fps. So, you really can’t use VMAF to decide which of the two files delivers a better viewing experience. This means that you can’t use VMAF to choose the best frame rates for files included in a hybrid-frame rate ladder.
Same deal with HDR. As explained in this Venera post, “to display the digital images on the screen, display devices need to convert the pixel values to corresponding light values. This process is usually non-linear and is called EOTF (Electro-Optical Transfer Function). Different types of “Transfer Functions” are supported in different display devices.” Summarizing from the Venera blog, SDR video uses the BT.709 transfer function, which is limited to 100 Nits (cd/m2), HDR displays use either the Perceptual Quantizer (PQ) or Hybrid Log-Gamma (HLG) transfer function which can extend up to 10,000 nits (though most HDR displays produce around 1000 nits).
Unless a video quality metric supports these HDR transfer functions the scores that it produces will measure only the SDR component of the video, which means that it will have a low correlation with subjective ratings of that video. It also makes it useless for comparing SDR and HDR videos to determine the relevant switch points.
Those measuring the quality of HDR videos have few options. Notably, the most recent version of the Moscow State University Video Quality Measurement Tool (VQMT) debuted three HDR versions of existing metrics; SSIM, MS SSIM, and VQM, though Moscow State was unable to share how those scores correlate with subjective evaluations.
Another is the SSIMPLUS VOD Monitor, which computes the SSIMPLUS metric and supports both HDR10 and DolbyVision HDR videos. The tool is also approved by Dolby Labs, and compatible with Dolby Profiles 5 and 8.
To test the accuracy of their HDR scores, SSIMWAVE compared the SSIMPLUS HDR ratings with two publicly available databases, and found a 98% correlation with subjective ratings from the first and an 85% correlation with the second. Unlike the three codecs supported in the Moscow State tool, SSIMPLUS can incorporate frame rate and color gamut into the analysis, and supports multiple device profiles to predict subjective ratings on a diverse range of devices from smartphones to 4K TVs (in the interest of full disclosure, the author produces training and marketing videos for SSIMWAVE).

As we saw, ATEME has created their own metric, the ATEME Quality Index, to supply the necessary analytics for their per-title encoding engine, and Brightcove has done the same, using their Perceptually-Weighted SSIM to fuel their per-title engine. If you want to build or evaluate per-title encoding schemes, you’ll need a video quality metric that can support the parameters adjusted by the metric. My go-to open-source metric, VMAF, is good for resolution and data rate, but stops there, unable to compare frame-rates or any parameters beneath that in table 1.
At this point in time (July 2021) the ideal per-title technology would be one that:
- Can change the number of rungs in the ladder
- Can change the resolution of rungs in the ladder
- Can change the data rate of the rungs in the ladder
- Divides the video into shots for encoding rather than arbitrary length GOPs or segments.
- Can incorporate multiple codecs based upon device data
- Can incorporate network performance
- Can adjust the frame rate
- Can adjust the dynamic range
- Can adjust color gamut
It doesn’t appear that any of the discussed products or services incorporate all these elements. In truth, unless you’re working with high frame rate, HDR content, you can lose the bottom three and just spitball when it’s best to downshift from full frame rate to half frame rate. If you’re a premium content producer working with video pushing the outer limits of quality, you’re going to want the ability to enable or disable all or most of them.
| Optimization | Netflix | Content Adaptive | Ateme | |
| Data rate | Yes | Yes | Yes | Yes |
| Number of rungs | Yes | Yes | Yes | |
| Rung resolution | Yes | Yes | Yes | |
| Codecs | Yes | Yes | ||
| Frame rate | Yes | Yes | ||
| Dynamic range | Yes | Yes | ||
| Color gamut | Yes | |||
| Other inputs | ||||
| Network data | Yes | |||
| Device data | Yes | Yes |



